Что такое эмбеддинги: как нейросеть понимает смысл текста
Введение
Понять, как нейросети схватывают смысл слов, фраз и целых документов, невозможно без одного ключевого механизма — эмбеддингов. Именно они позволяют моделям превращать язык в математику и работать с этим языком так, словно у них есть внутреннее понимание написанного. В последние годы с ростом популярности технологий искусственного интеллекта слово эмбеддинги звучит все чаще, однако мало кто взялся доступно объяснить, что же скрывается за этим фундаментальным термином. В этой статье специалисты компании ServerFlow расскажут вам, что из себя представляют эмбеддинги в нейросетях, как работает векторизация, почему она стала основой для создания RAG-систем и как этот механизм облегчает реализацию локального развертывания LLM.
Что такое эмбеддинги в нейросетях?
Эмбеддинги — это векторные представления объектов: слов, фраз, документов, изображений, звука. Иначе говоря, это способ записать смысл объекта набором чисел. Когда мы говорим эмбеддинги в искусственном интеллекте, мы имеем в виду два связанных явления:
- Нейросеть сжимает сложный объект до компактного вектора фиксированной длины — например, 768 или 4096 чисел.
- Расстояние между двумя такими векторами показывает их смысловую близость.
Так появляется векторное представление слов. Например, у слова “кофе” будет вектор, рядом с которым в пространстве окажутся слова “чай”, “капучино”, “эспрессо”, но точно не слова “процессор”, “материнка”, “Linux”.

Как нейросеть воспринимает слова в пространстве представлений. Источник: .
В машинном обучении эмбеддинги стали незаменимым инструментом: грубо говоря, они переводят тексты, изображения, видео или звуки с человеческого представления на язык математики, понятный машине. На ряду с этим, эмбеддинги также выступают в роли неких координат в многомерном смысловом пространстве, где чем ближе векторы, тем больше слов связаны общим смыслом.
Как работает векторизация текста
Процесс получения эмбеддингов называют векторизацией текста. Он начинается с токенизации — разбиения текста на минимальные единицы, которыми оперирует модель. Это могут быть слова, части слов или даже отдельные символы. Затем эти токены проходят через слои нейросети: внимание, линейные преобразования, нормализации и активации. На каждом этапе сеть ищет статистические связи и распределяет токены по многомерному пространству так, чтобы похожие смыслы получали похожие координаты.
Векторизация данных делает текст математическим объектом. Математика удобна тем, что с векторами можно выполнять точные операции: измерять расстояние между ними, вычислять угол, находить ближайшие точки. Поэтому векторное пространство слов — не метафора, чтобы убедить непонимающих юзеров заумными словами, а реальный вычислительный инструмент. Затем полученные векторы переходят в хранилище смыслов, с которыми модель может работать напрямую — оно называется векторным пространством — если два предложения говорят о похожем явлении, то их вектора окажутся рядом, даже если формулировки различаются полностью. Это отличает эмбеддинги от старых методов вроде bag-of-words или TF-IDF, где сходство определялось совпадением слов, а не смыслов.

Различие между неструктурированными данными и их векторными представлениями. Источник: .
Почему эмбеддинги важны для понимания смысла
Эмбеддинги — это не просто числа, а память смыслов, накопленная моделью. Модели не имеют знаний в человеческом понимании, но имеют структуру смысловой близости. Благодаря этой структуре они способны понимать контекст слов, оценивать смысловую совместимость фраз, обобщать новые данные, даже если они не были задействованы во время обучения. Именно благодаря эмбеддингам нейросеть способна понимать то, с чем она ранее никогда не сталкивалась — в противном случае, объемы данных при обучении измерялись бы не в терабайтах, а в зеттабайтах, что могло бы похоронить ИИ-индустрию еще в зародыше.
Эмбеддинги и смысл текста связаны тем, что числа отражают контекст: модель учитывает соседние слова, стиль, роль токена, грамматику, тему, эмоциональный фон. Благодаря этому она может обобщать смысл. Если модель видит фразу “многопоточная производительность”, она может предположить, что речь идет о процессоре, даже если это слово отсутствует в пользовательском запросе. Эмбеддинги и контекст работают вместе: значение токена меняется в зависимости от окружения, поэтому у современных моделей эмбеддинги — не просто статическая таблица, а динамическое представление. Токены приобретают значение только внутри фразы, а не вне ее. Токен сам по себе ничего не значит, но его эмбеддинг — значит все. Поэтому разговор о “понимании” моделей всегда сводится к качеству их эмбеддингов.

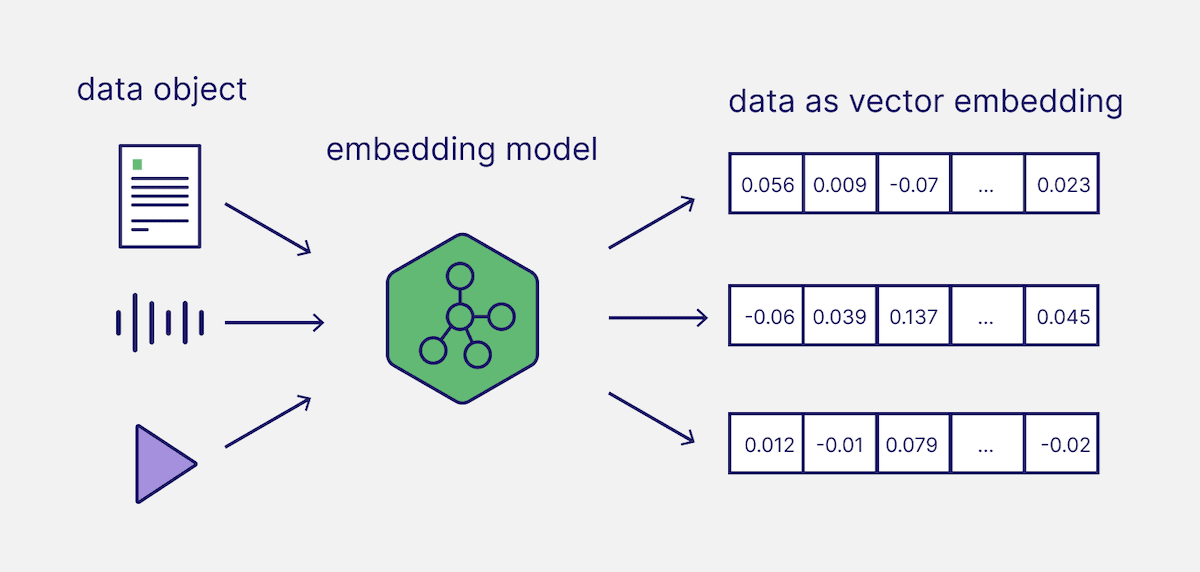
Как нейросеть переводит объекты в эмбеддинги. Источник: .
Поиск по смыслу текста с эмбеддингами
Все ведь знают про такое понятие, как семантический поиск? Именно благодаря этой системе популярные поисковики, такие как Google или Яндекс, совершили внушительный скачок эффективности, ведь если раньше запрос сравнивался со страницами по совпадению слов, что часто приводило к ошибкам из-за разной лексики, то теперь нужная информация находится за считанные секунды. Тот же механизм работает и в ИИ, ведь семантический поиск базируется на векторизации данных. Это достигается тем, что и запрос, и документы векторизуются. Затем система ищет те точки в векторном пространстве, которые ближе всего к запросу. Для этого используются векторные базы данных — специальные хранилища, оптимизированные под поиск ближайших соседей в многомерном пространстве. Они могут содержать миллионы и миллиарды векторов, обеспечивая быстрый поиск за доли секунды.
Векторное хранилище полностью меняет подход к информации. Раньше мы искали совпадения по словам, теперь мы ищем совпадения по идеям. Такой поиск не требует точной формулировки запроса, не зависит от ошибок пользователя и может выдавать результаты, которые человек сам бы не смог сформулировать, но которые полностью отвечают его задаче.
Если пользователю нужно найти “как улучшить скорость nginx”, он получит статью “оптимизация веб-сервера”, даже если слово “nginx” там не упоминается. Это и есть сила поиска по эмбеддингам и векторным базам знаний.
Что такое RAG и как он использует эмбеддинги
RAG (Retrieval-Augmented Generation) — это архитектура, которая позволяет нейросети отвечать на вопросы, опираясь не только на свои параметры, но и на внешние данные.
Схема выглядит так:
- Пользователь задает вопрос;
- Система строит эмбеддинг запроса;
- Ищет в векторной базе знаний релевантные документы;
- Передает их в LLM, которая формирует итоговый ответ.
То есть RAG — это не просто генерация через ИИ, а поиск по смыслу и только потом генерация ответа.
Сильная сторона RAG в том, что он снижает галлюцинации и делает датасет нейросети актуальным на сегодняшний день, даже если сама LLM обучена несколько лет назад. Но без эмбеддингов он бы просто не работал: именно векторизация формирует мост между вопросом пользователя и данными, которые система должна извлечь. RAG стал стандартом для корпоративных ИИ-решений, чат-ботов, поисковых систем документов и локальных справочных ассистентов. Если вы хотите подробнее узнать о RAG-технологиях и их передовых функциях, вам сюда.
Где применяются эмбеддинги кроме текста
Эмбеддинги — это не только про слова. Любые данные, которые можно “сжать” до вектора, становятся пригодными для анализа.
Например, эмбеддинг изображения — это вектор, извлекаемый визуальной нейросетью (обычно CNN или Vision-Transformer). Он описывает содержание изображения: объекты, стиль, цветовую структуру. Поэтому модели могут искать похожие фотографии, группировать товары по внешнему виду и решать задачи компьютерного зрения без ручной разметки. Эмбеддинги применяются в музыке (поиск по звучанию), в рекомендациях (векторизация нейросети описывает интересы пользователя) и даже в анализе графов. Фактически эмбеддинги — это один из универсальных языков искусственного интеллекта. Они создают общий формат данных, который понимают разные ИИ-модели, вне зависимости от ее датасета, количества параметров и токенизатора.

В эмбеддинги можно перевести любые типы данных. Источник: .
Примеры эмбеддингов в популярных моделях
Современные модели активно используют встроенные эмбеддинги и позволяют генерировать собственные.
Несколько наиболее распространенных примеров:
- Эмбеддинги в LLaMA*. Модель использует собственные токеновые и позиционные эмбеддинги, а также поддерживает подключение внешних генераторов векторных представлений через мини-модели. Это позволяет строить семантические векторы слов, предложений и документов для локальных RAG-систем, обеспечивая точное сопоставление смысловых фрагментов.
- Эмбеддинги в DeepSeek. Векторные представления DeepSeek ориентированы на технические, математические, программные домены. Модель создает высокоточную семантическую структуру, выделяя логические и функциональные зависимости между концептами, что делает возможным точное ранжирование и поиск по смыслу в сложных инженерных задачах.
- Эмбеддинги в Gemma. Пространство эмбеддингов Gemma ориентировано на формализованные знания и строгую структурированность. Векторы фиксируют технические и концептуальные взаимосвязи между объектами, обеспечивая точное соответствие семантической структуры и содержания документа.
- Эмбеддинги в GPT-OSS. Модель формирует универсальные текстовые эмбеддинги, совместимые с RAG и семантическим поиском. Векторы GPT-OSS отражают контекстную и тематическую структуру текста, различая технические домены и обеспечивая консистентное расположение переформулированных токенов в семантическом пространстве.
Выводы
Эмбеддинги — это язык, на котором нейросети понимают смысл ваших запросов. Они превращают текст, изображение или любую другую сущность в числовой вектор, который говорит модели, что именно означает объект и чем он похож на другие объекты. Без эмбеддингов невозможны ChatGPT, DeepSeek, RAG-системы, системы семантического поиска, генераторы рекомендаций и любые локальные LLM-решения. Именно они позволяют моделям думать не словами, а смыслами — и поэтому современные ИИ-системы так хорошо понимают, что пользователи требуют от них. Если вы хотите знать больше о внутренней кухне искусственного интеллекта, то посетите блог ServerFlow — мы говорим о технологиях и железе так, чтобы было понятно как разработчикам и системным администраторам, так и обычным юзерам.
*LLAMA — проект Meta Platforms Inc.**, деятельность которой в России признана экстремистской и запрещена
**Деятельность Meta Platforms Inc. в России признана экстремистской и запрещена
