Что такое токен в языковых моделях (LLM) и ChatGPT: простыми словами и на практике
Введение
Вы когда-нибудь задумывались, за что именно вы платите, когда используете ChatGPT, Claude или API других ИИ-разработчиков? В счетах, прайс-листах и документации фигурирует одно загадочное понятие — токены. Именно за них и списываются средства, причем суммы могут быть весьма внушительными. Но даже если вы не платите деньги, а просто запускаете нейросеть локально, в vLLM или Ollama, вы постоянно сталкиваетесь с ограничениями вроде “контекст 128 тысяч токенов” или “поддержка до 1 миллиона токенов”. Что же скрывается за этим столь распространенным в ИИ-индустрии понятием? Что это за единица измерения, которая диктует возможности модели и размер наших затрат? В этой статье специалисты компании ServerFlow расскажут вам, что такое токены, как их считать, откуда они появились и почему они так сильно влияют на стоимость, возможности и производительность языковых моделей.
Что такое токен и почему он важен для ИИ
Если говорить простыми словами, то токен — это минимальная единица текста, с которой работает языковая модель. Это не всегда целое слово, и в этом заключается ключевое отличие от нашего человеческого восприятия текста. Чаще всего токеном является часть слова, одно слово или даже отдельный символ, включая знаки препинания и пробелы. Рассмотрим наглядные примеры. Простое слово “код” для большинства моделей — это один токен. Более сложное слово “нейросеть” часто разбивается на два токена: “нейро” и “сеть”. А фраза “Hello, world!” превращается в три токена: “Hello”, “,” и “world!”. Важно понимать, что в контексте ИИ токен — это не какая-то определенная валютная единица и не криптографический ключ для разблокировки возможностей ИИ. Это фундаментальный элемент, кирпичик, из которого модель строит свое понимание контекста и генерацию текста.
Такой подход позволяет моделям гибко и эффективно работать с огромными словарями, включая редкие слова, профессиональную терминологию или неологизмы, разбивая их на уже знакомые, часто встречающиеся фрагменты. Без токенизации словарь модели был бы необъятным и крайне неэффективным, а сама модель — громоздкой и медленной. Как говорил CEO компании Nvidia Дженсен Хуанг: “Токены открыли новый рубеж — первый шаг в необыкновенный мир, где рождаются бесконечные возможности, где сырые данные становятся инструментом нового вида восприятия”.
Как модели LLM работают с токенами
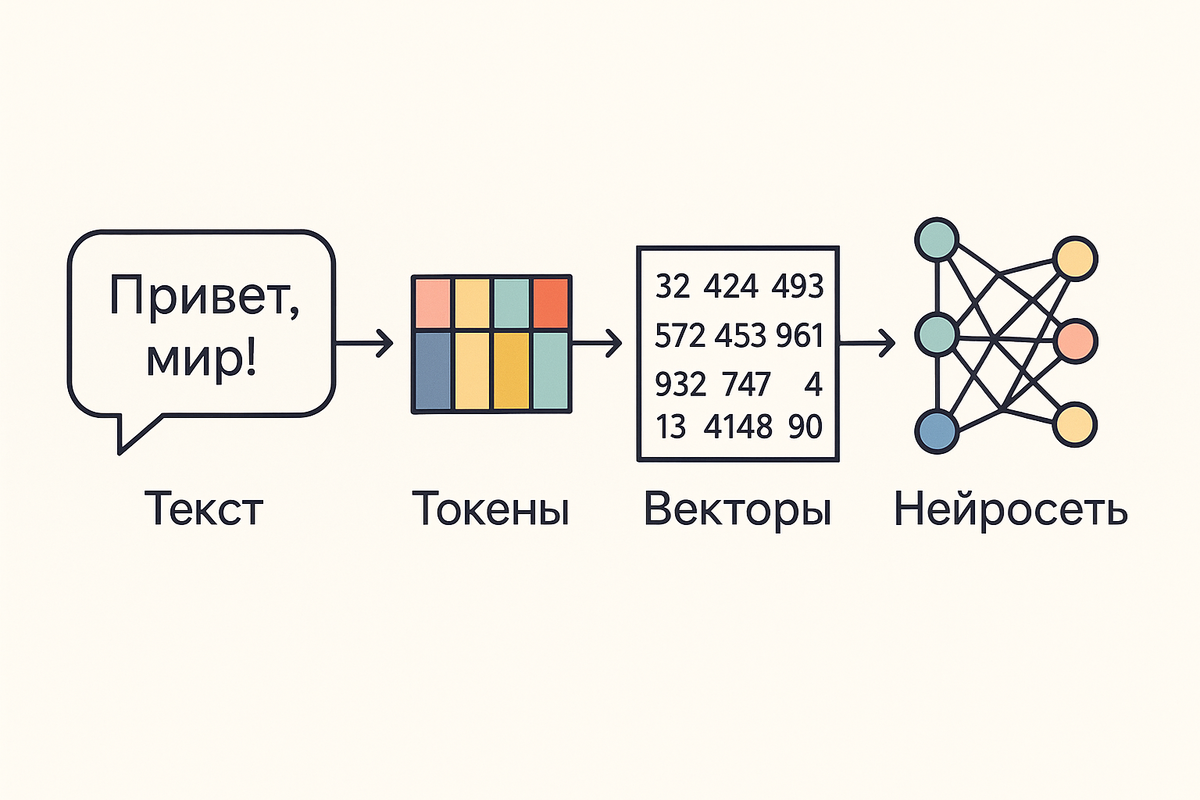
Процесс работы модели с текстом напоминает хорошо отлаженный конвейер, и токены играют в нем центральную роль. Все начинается с этапа токенизации, когда исходный текст, который вы вводите, разбивается на эти самые токены. Каждому полученному токену присваивается уникальный числовой идентификатор, потому что нейросети, в своей основе, оперируют числами, а не буквами.
На следующем, критически важном этапе, эти числовые идентификаторы превращаются в эмбеддинги — специальные числовые векторы в высокоразмерном пространстве. Каждый вектор носит в себе семантическую сущность и контекстуальные связи своего токена. Именно в форме эмбеддингов модель понимает и чувствует текст. Токен “процессор” будет иметь эмбеддинг, близкий к эмбеддингу “процессы”, но далекий от эмбеддинга “транзистор”.
После этого запускается процесс инференса, или логического вывода. Модель, используя механизм внимания, анализирует последовательность токенов-эмбеддингов в контексте и предсказывает, какой токен должен быть следующим. Здесь же в игру вступает такой технологический элемент, как KV-кэш (Key-Value cache), который позволяет модели эффективно “помнить” контекст предыдущих токенов, не пересчитывая его каждый раз заново для генерации каждого нового слова. Таким образом, языковая модель не оперирует целыми словами или предложениями — она использует последовательности токенов, предсказывая каждый следующий “кирпичик” текста на основе предыдущих. Ее мышление — это непрерывный поток токенов.

Принцип токенизации и фильтрации текста моделью искусственного интеллекта. Источник: .
Что такое токенизация текста и зачем она нужна
Токенизация — это именно тот процесс, который преобразует сырой текст в последовательность токенов, готовых к обработке моделью. Это критически важный и далеко не самый простой шаг, поскольку от выбора алгоритма токенизации напрямую зависит, как модель будет воспринимать входные данные, насколько точно она поймет смысл и как эффективно будет использовать свой контекст.
Разные модели и платформы используют разные токенайзеры, обученные на различных корпусах данных. У OpenAI есть собственный высокооптимизированный инструмент под названием tiktoken. В экосистеме Hugging Face популярны токенайзеры на базе алгоритма BPE (Byte-Pair Encoding), который итеративно объединяет самые частые пары байт или символов. А такие модели, как LLaMA*, используют алгоритм SentencePiece, который не зависит от предварительной разметки на слова.
Почему нельзя использовать единый стандарт? Все просто — потому что эффективность токенизации сильно зависит от языка ввода запроса, специфики данных, на которых обучалась модель, и поставленных задач. Один и тот же текст, пропущенный через разные токенайзеры, может дать разное количество токенов, что напрямую скажется на стоимости обработки и на том, поместится ли запрос в контекстное окно. К примеру, слово “виртуализация” может быть одним токеном в одной модели и быть разбито на несколько (“вирту”, “али”, “за”, “ция”) в другой. Именно поэтому при оценке длины текста для LLM всегда лучше считать именно токены, а не слова или символы, так как последние дают очень неточную картину.

Токенизаторы у разных ИИ-моделей кардинально отличаются по принципу перевода текста в токены. Источник: .
Контекстное окно и лимит токенов
Одной из ключевых характеристик любой современной LLM является размер ее контекстного окна. Это и есть тот самый лимит токенов — максимальное общее количество токенов (как входных, так и сгенерированных в ответе), которое модель может принять и обработать за один вызов (запрос). Это окно можно представить как оперативную память или кратковременную память модели: в нее должен физически поместиться весь ваш запрос, вся история диалога и ответ, который ей предстоит сгенерировать.
Во времена начала бурного развития ИИ-индустрии контекстное окно ИИ-моделей было очень ограничено, но его размер увеличивался по экспоненте. Например, у GPT-3.5 Turbo контекстное окно составляло 16 тысяч токенов, у GPT-4 — уже 128 тысяч, а у таких моделей, как Claude 4.5 и Gemini 2.5 Pro, контекстное окно достигает 1-2 миллионов токенов, что эквивалентно нескольким объемным романам. Что происходит, когда этот лимит превышается? Модель вынуждена “забывать” самую раннюю информацию из диалога, так как просто физически не может ее обработать. Существуют техники скользящего окна, когда модель работает только с последними N токенами, игнорируя начало. Именно поэтому в длинных и сложных беседах ChatGPT иногда теряет нить разговора, начинающуюся несколько тысяч слов назад. Примечательно, но многие пользователи этого просто не понимают, ругая OpenAI за их “забывчивого” и “тормознутого” чат-бота, который не может удержать сути разговора. Именно для того, чтобы понять фундаментальные ограничения нейросетей и основные принципы их работы, нужно понимать, что из себя представляет токен и на что он влияет.
Токены в ChatGPT и GPT-5: как считать и за что платим
Когда вы пользуетесь платными сервисами вроде OpenAI API, вы платите именно за токены. Причем бухгалтерия в компании Сэма Альтмана ведется очень строго: отдельно считаются входные токены (те, что вы отправили в запросе, включая историю беседы) и выходные токены (те, что модель сгенерировала в ответе). Ориентировочно, 1000 токенов эквивалентны примерно 750 словам английского текста, но для русского языка это соотношение может быть иным, часто в сторону большего количества токенов на то же количество слов, из-за морфологической сложности языка.

Текст этой статьи, переведенный в токены через токенайзер OpenAI GPT-4o. Источник: .
Чтобы заранее оценить стоимость или длину своего промпта, можно воспользоваться официальным интерактивным инструментом OpenAI Tokenizer или установить библиотеку tiktoken для Python, которая позволяет программно подсчитывать токены в тексте. Вы просто вставляете свой текст и видите, на какие токены он разобьется и каково их общее количество. Понимание этого механизма — ключ к оптимизации расходов. Короткие, ясные и хорошо структурированные промпты, которые эффективно используют доступное контекстное окно, позволяют значительно снизить стоимость использования коммерческих LLM. Например, если вы знаете, что контекст ограничен, можно не загружать модель полной историей переписки, а отправлять только самые релевантные выдержки.

Отличия разных токенизаторов GPT наглядно. Источник: .
Выводы
Токен — это не просто сухой технический термин, а фундаментальный компонент мышления и базовый ресурс для любой современной языковой модели. Это универсальная валюта, в которой измеряются и вычислительные затраты, и объем памяти модели, и итоговая стоимость инференса. Для разработчиков, технических руководителей и инженеров ИИ-систем глубокое понимание работы с токенами, от тонкостей токенизации до стратегического управления контекстным окном, открывает путь к созданию более эффективных, быстрых и экономичных решений на базе искусственного интеллекта. Оптимизация промптов, осознанный выбор моделей с подходящим размером контекста и постоянный контроль за расходом токенов напрямую и измеримо влияют на итоговую стоимость и производительность внедренных LLM. Токенизация остается мостом между человеческим языком и цифровым разумом, и понимание этого моста — первый шаг к достижению настоящего мастерства в работе с искусственным интеллектом. Если вы хотите узнать больше об искусственном интеллекте и железе, на котором его запускают, добро пожаловать в блог компании ServerFlow!
*LLAMA — проект Meta Platforms Inc.**, деятельность которой в России признана экстремистской и запрещена
**Деятельность Meta Platforms Inc. в России признана экстремистской и запрещена
