Что такое KV Cache и как он ускоряет работу языковых моделей (LLM)
Введение
Как вы помните, основным минусом архитектуры трансформеров, стоящей в основе всех топовых LLM, является последовательная генерация текста, при которой каждый новый токен должен учитывать весь предыдущий контекст диалога. В результате этой причуды, вычислительная нагрузка при инференсе LLM растет экспоненциально, и если бы проблему не удалось решить, локальные нейросети оставались бы доступными только владельцам ИИ-кластеров. На помощь пришла компания OpenAI, которая первой предложила сохранять Key и Value между шагами генерации. Так и появился передовой подход оптимизации скорости работы LLM под названием KV Cache. В этой статье специалисты компании ServerFlow расскажут вам, что из себя представляет KV Cache, как он работает, где применяется и какие перспективы развития этой технологии существуют.
Что такое KV Cache и зачем он нужен?
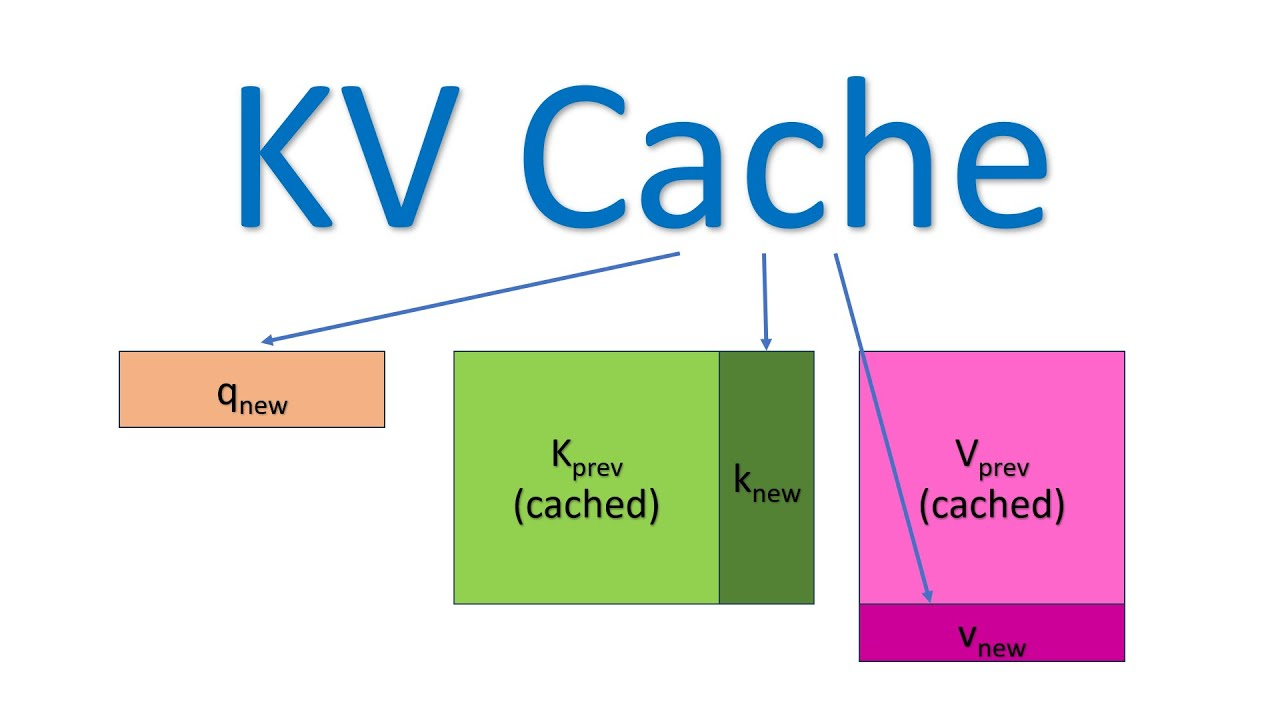
KV Cache — это механизм кэширования промежуточных вычислений в архитектуре трансформеров, который сохраняет ключи (Key) и значения (Value) для всех предыдущих токенов во время инференса. Без KV Cache модель вынуждена была бы пересчитывать матрицы Key и Value для всей последовательности при генерации каждого нового токена, что создавало бы квадратичную зависимость (O(n²)) между длиной контекста и требуемыми вычислениями. С использованием кэша сложность снижается до линейной (O(n)), поскольку новые вычисления выполняются только для последнего токена, а для всех предыдущих используются закэшированные значения. Технически KV Cache хранит выходные значения ключей и значений для каждого слоя внимания и для каждой "головы" внимания в модели. При генерации очередного токена механизм внимания использует текущий токен как Query (запрос), а все Key и Value из кэша — для расчета весов внимания и итогового представления.

Как KV-Cache сохраняет ключи и значения токенов во время инференса. Источник: .
Как работает KV Cache в трансформерах
Процесс генерации с KV Cache разделяется на две четкие фазы: префилл и декодирование.
Фаза префилла (Prefill):
- Модель получает входной промпт (начальный текст);
- Обрабатывает всю последовательность промпта целиком;
- Вычисляет и сохраняет в кэш матрицы Key и Value для каждого токена промпта;
- Выполняется однократно перед началом генерации.
Фаза декодирования (Decoding):
- Берется последний сгенерированный токен как Query;
- Из кэша извлекаются все предыдущие Key и Value;
- Вычисляется внимание между новым Query и закэшированными Key;
- Генерируется следующий токен;
- Обновляется кэш добавлением Key и Value для нового токена.
Объем памяти, занимаемый KV Cache, линейно зависит от трех основных параметров: длины контекста (количество токенов), количества слоев в модели и числа голов внимания. Для крупных моделей с длинными контекстами он может составлять гигабайты видеопамяти, но даже эти условности не идут ни в какие сравнения с системными ресурсами, сжираемыми голым трансформером без KV Cache.

Схема работы технологии KV-Cache. Источник: Arxiv.
KV Cache в популярных движках LLM: от vLLM до Ollama
Различные движки инференса реализуют и оптимизируют KV Cache по-разному, предлагая уникальные подходы к управлению памятью и ускорению вычислений.
Таблица поддержки KV Cache в ИИ-движках:
|
Движок |
GPU KVCache |
CPU KVCache |
Оффлоад (RAM/SSD) |
Квант. KVCache |
Комментарий |
|
✅ Да |
⚙️ Частично (через backend) |
✅ (Paged KV-Cache) |
⚙️ FP8/INT8 поддерживается |
Один из лучших по оптимизации KV-Cache | |
|
✅ Да |
✅ Да |
⚙️ Через vLLM backend |
⚙️ частично |
Объединяет PyTorch + vLLM | |
|
✅ Да (GPU оффлоад) |
✅ Да |
✅ SSD-оффлоад |
✅ Q4-Q8 |
Максимально гибкий | |
|
✅ Да (через llama.cpp) |
⚙️ |
✅ SSD-оффлоад |
✅ Q4_K_M |
Завязан на llama.cpp | |
|
✅ Да (GPU) |
⚙️ Нет оффлоада |
⚙️ частично |
✅ Q4–Q6 |
GUI-ориентированный клиент, не всегда дает полный контроль |
Особенности реализации KV Cache в ИИ-движках
Хотя сама идея KV Cache универсальна, ее реализация в разных LLM-бэкендах существенно отличается. Это связано с архитектурными особенностями, подходами к управлению памятью и целевыми сценариями — от серверного инференса на мощных GPU до оффлайн-запуска моделей на пользовательских ПК. Ниже рассмотрим, как разные системы решают задачу хранения и доступа к ключам (Key) и значениям (Value).
KV Cache в vLLM
vLLM внедрил одну из самых передовых реализаций — PagedAttention. Вместо того чтобы размещать KV-кеш непрерывно в памяти GPU, как это делалось ранее, vLLM разбивает кеш на страницы фиксированного размера. Это решает проблему фрагментации памяти и позволяет динамически перераспределять ресурсы между несколькими запросами. Такое решение критично при выполнении инференса в нескольких пользовательских сессиях. Поскольку страничный подход поддерживает переиспользование выделенных блоков, достигается прирост скорости до 24x относительно базовой реализации.
KV Cache в SGLang
SGLang использует другой подход — HiCache, иерархическую систему кеширования. Ее идея состоит в том, чтобы распределить KV Cache по уровням хранения: наиболее востребованные ключи и значения находятся в GPU, менее используемые перемещаются в CPU-память, а редко запрашиваемые — на NVMe-накопитель. При правильной настройке HiCache обеспечивает до 80 % попаданий в кеш, что снижает задержки при генерации и позволяет работать с контекстами длиной свыше 64 000 токенов.
KV Cache в llama.cpp
В llama.cpp, ориентированном на локальный инференс на потребительских GPU, KV Cache реализован как собственный механизм хранения тензоров ключей и значений. Буферы кеша организованы по слоям и головам внимания и работают по принципу ring buffer с прямым индексным доступом. Память выделяется непрерывными блоками (chunk allocation), что снижает накладные расходы при обращениях. При нехватке VRAM кеш может быть частично перенесен в системную память за счет оффлоада с помощью флага -nkvo — данные отображаются через mmap и динамически подгружаются при обращении. Это позволяет использовать модели даже на видеокартах с 6-8 ГБ памяти. В сочетании с оптимизациями FlashAttention llama.cpp демонстрирует сбалансированное решение по скорости и экономии ресурсов среди локальных движков.
KV Cache в Ollama и LM Studio
Ollama и LM Studio делают ставку на компактность и квантование: кеш может храниться в форматах FP8 и Q4 (INT4), что снижает его объем в 2-4 раза по сравнению с FP16 без заметной потери качества генерации. Оба движка поддерживают и частичный оффлоад KV Cache — при нехватке VRAM данные могут переноситься в системную память, по сути реализуя упрощенную форму CPU-spill, аналогичную решениям в vLLM и SGLang. В результате даже средние GPU способны удерживать длинные контексты, а общая архитектура кеша остается оптимизированной под пользовательские системы, где каждый гигабайт видеопамяти критичен.
Длинный контекст и память GPU: как KV Cache экономит ресурсы
Неужели KV Cache просто помогает сократить системные требования для инференса LLM? На самом деле, не только — эта технология еще и отлично оптимизирует управление памятью и работу с длинным контекстом. Для небольшой модели LLaMA*-7B с контекстом 12,000 токенов в формате FP16 одни только только веса занимают примерно 13 ГБ VRAM, а при увеличении контекстного окна — эти значения можно смело удваивать на два. Без оптимизации работа даже с такой сравнительно крошечной нейронкой была бы просто невозможна на топовом потребительском железе.
KV Cache обеспечивает двустороннюю экономию ресурсов: сокращение как количества вычислений, так и уменьшение использования памяти. Без кэша сложность операций внимания росла бы квадратично с увеличением длины контекста, делая генерацию неприлично медленной уже при нескольких тысячах токенов. С кэшем сложность остается линейной, что сохраняет производительность даже при значительном увеличении контекста.
Технология Paged KV Cache, развивающая идеи PagedAttention, оптимизирует управление памятью через страничную организацию кэша, динамическое перераспределение страниц между запросами и поддержку неоднородных длин контекста в батчах. Это значительно уменьшает накладные расходы на управление памятью.
Квантование кэша также стало стандартной практикой оптимизации инференса LLM. FP8-квантование сокращает объем памяти вдвое по сравнению с FP16, а форматы INT4 и FP4 обеспечивают 4-кратное сжатие. Современные исследования показывают, что квантование KV Cache до INT8/FP8 практически не влияет на качество генерации, а поддержка квантованного кэша в FlashAttention 3 обеспечивает дополнительное ускорение.
FlashAttention и его развитие в версиях 2 и 3 не заменяют KV Cache, а идеально дополняют его, оптимизируя сами вычисления внимания. FlashAttention снижает количество операций ввода-вывода с памятью, а FlashAttention 3 добавляет поддержку FP8 и улучшенное распараллеливание. Совместное использование этих технологий дает синергетический эффект — до 2-кратного ускорения на передовых ИИ-ускорителях H100.

KV-Cache на 37,9% ускоряет инференс больших языковых моделей. Источник: .
Современные тенденции в KV Cache: оффлоад, иерархия и квантование
Эволюция KV Cache движется в направлении создания более интеллектуальных и эффективных систем управления памятью, способных работать с экстремально длинными контекстами при минимальных аппаратных требованиях.
Иерархический кэш и оффлоад
Современные системы, такие как HiCache в SGLang, реализуют сложные иерархии памяти, где:
- Горячие данные (активные части контекста) хранятся в быстрой GPU-памяти.
- Теплые данные могут перемещаться в CPU RAM.
- Холодные или редко используемые части контекста вытесняются на NVMe-накопители.
- Интеллектуальные алгоритмы предсказания определяют, какие данные понадобятся на следующем шаге генерации.
Глубокое квантование и смешанная точность
Новые подходы к квантованию KV Cache та же демонстрируют впечатляющую эффективность благодаря передовым функциям. К этим функциям относятся:
- Динамическое квантование, где разные слои модели используют разную точность.
- Адаптивные схемы квантования, учитывающие важность различных частей контекста.
- FP8 как стандарт де-факто для продакшн-систем.
- INT4 квантование для специализированных сценариев с экстремальными требованиями к памяти.
PagedAttention и эволюция управления памятью
Второе поколение систем управления памятью для KV Cache приносит:
- Улучшенные алгоритмы предварительной выборки.
- Более эффективное сжатие словаря кэша.
- Поддержку sparse attention в сочетании с KV Cache.
- Оптимизации для многомодальных моделей.
Выводы
KV Cache превратился из технической оптимизации в фундаментальный компонент архитектуры современных LLM-систем. Его значение невозможно переоценить — без KV Cache работа с длинными контекстами и массовое развертывание LLM были бы экономически и технически нецелесообразными. Современные реализации демонстрируют, что наибольший практический эффект от испоользования KV Cache достигается в комбинации с PagedAttention для эффективного управления памятью и FlashAttention 3 для ускорения вычислений. Этот симбиоз стал полноценным отраслевым стандартом для высокопроизводительных систем инференса. Но на этом развитие технологии не заканчивается и уже сейчас KV Cache активно эволюционирует для создания еще более интеллектуальных систем, способных адаптивно управлять ресурсами, прогнозировать паттерны доступа и эффективно работать в гетерогенных вычислительных средах. Иерархический кэш, глубокое квантование и тесная интеграция с аппаратным ускорением — это три кита, на которых будет строиться следующее поколение технологий ускорения LLM-инференса. ServerFlow регулярно разбирает технологии ускорения LLM — от FlashAttention и PagedAttention до KV Cache. Читайте наш блог, чтобы понимать, как извлечь максимум производительности из своего GPU-сервера.
