Эпоха ИИ-трансформеров: что это за архитектура и как работает механизм внимания
Введение
В 2017 году скромная научная статья под названием “Attention Is All You Need” сделала прорыв в ИИ-индустрии, предложив миру перейти от устаревших RNN-моделей к новой, перспективной архитектуре нейросетей — ИИ-трансформеры. Идея отлично прижилась и сегодня трансформеры стали фундаментом, на котором стоят буквально все современные большие языковые модели, занимающие топы ИИ-рынка. Именно трансформеры перевели нейросети из ниши слабых, узкоспециализированных инструментов, которые уже уперлись в свой технологический предел, в эпоху генеративных моделей, где слово “интеллект” выходит на первый план, оставляя слово “искусственный” позади. В этой статье специалисты компании ServerFlow популярно, но с учетом всех технических тонкостей, расскажут вам, что из себя представляют модели трансформеры, какие механизмы лежат в их основе, и какие семейства нейросетей являются главными популяризаторами движения языковых моделей.
Что такое трансформер в нейросетях и как он работает?
Трансформеры — это архитектура нейронной сети, которая отказалась от последовательной обработки данных, характерной для рекуррентных сетей (RNN), в пользу параллельного анализа всех элементов входной последовательности (пользовательского запроса) сразу. Если RNN читала текст слово за словом, с большим трудом удерживая в памяти начало длинного предложения, то трансформер просматривает его целиком, как человек просматривает страницу книги, моментально оценивая взаимосвязи между всеми словами и предугадывая следующие последовательности.
За реализацию этой функции отвечает механизм внимания (Attention) — мозг трансформера. Он помогает модели определять, какой “контекст” имеет пользовательский запрос, чтобы затем уделить конкретным частям входных данных больше “внимания” при генерации ответа. Подробнее об этой передовой системе мы поговорим немного ниже, а пока давайте рассмотрим, какие еще компоненты входят в архитектуру ИИ-трансформеров.
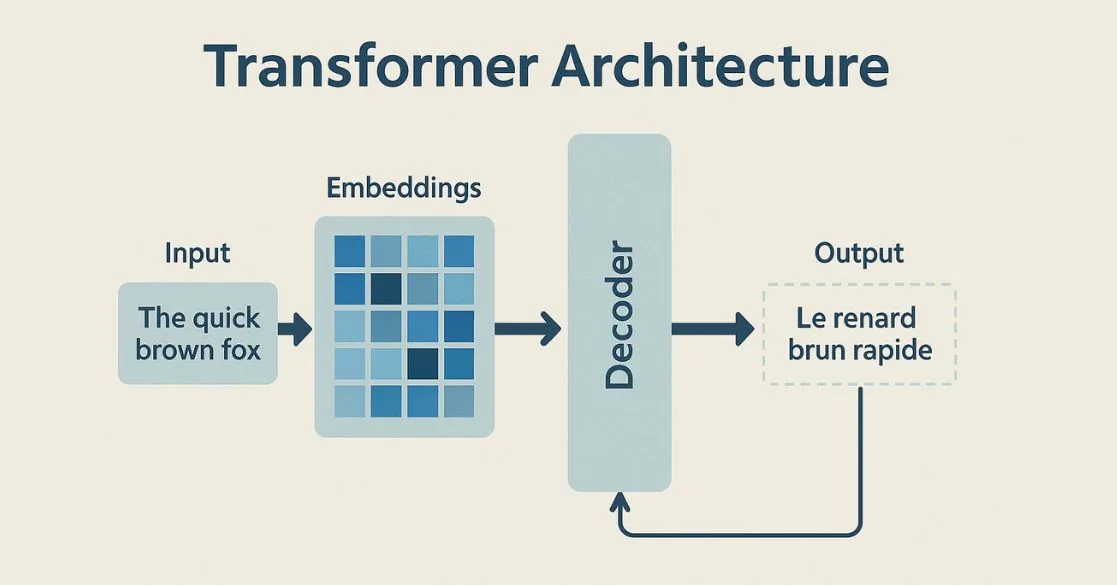
Архитектурно любые модели-трансформеры состоят из двух основных частей — энкодера (кодировщика запроса пользователя) и декодера (декодировщика ответа нейросети), которые, в свою очередь, собраны из еще нескольких блоков, каждый из которых отвечает за конкретную функцию:
- Слой эмбеддинга для перевода слов на язык нейросети, то есть в числовые векторы.
- Многоголовое внимание (Multi-Head Attention) для параллельного анализа контекста запроса.
- Простейшую полносвязную нейросеть (Feed Forward) для прямолинейной обработки информации внутри блока.
- Остаточные связи (Residual Connections) для того, чтобы перебрасывать информацию между другими слоями нейросети.
- Слой нормализации (LayerNorm) для стабилизации обучения глубокой сети.
Некоторые из этих компонентов базируются на фундаментальных принципах технологий искусственного интеллекта, которые вывели еще в середине прошлого века. Если вам интересно узнать, как эволюционировали ИИ-модели от примитивных перцептронов и MLP до современных трансформеров и диффузионных нейросетей, рекомендуем ознакомиться с этой статьей.

Архитектура ИИ-трансформеров и ее ключевые компоненты. Источник: .
Как работает Attention-механизм: внимание вместо памяти
С фундаментальными элементами трансформеров мы разобрались, поэтому переходим к анализу внутренностей механизма внимания. А чтобы вам было проще понять, как он работает, приведем простой пример.
Представьте, что вы переводите предложение: “The processor increased the fan speed because it was overheating”. Чтобы правильно понять слово “it”, вам нужно понять, что оно относится к “processor”, а не к “fan”. Рекуррентные сети для этого вынуждены были “протащить” информацию о “processor” через всю последовательность слов, рискуя ее забыть. Attention-механизм решает эту проблему элегантно: он позволяет каждому слову в предложении “взаимодействовать” с каждым другим словом, напрямую определяя силу их связи.
Работа Attention строится на трех основных сущностях, которые курируют внимание нейросети, выступая в роли некого контроллера ее действий:
- Query (Запрос): Что я ищу? (например, слово “it”).
- Key (Ключ): Как я могу быть описан? (каждое слово в предложении предлагает свой ключ).
- Value (Значение): Какую информацию я несу? (семантическое содержание каждого слова).
Механизм вычисляет, насколько каждый Query соответствует каждому Key, получая веса внимания (Attention Weights), которые показывают степень важности других слов. Затем эти веса используются для построения взвешенной суммы из Value, создавая обогащенное контекстом представление слова.
Self-Attention — это когда Query, Key и Value извлекаются из одной и той же последовательности (например, входного предложения). Multi-Head Attention позволяет модели одновременно фокусироваться на разных типах связей — например, на грамматических и семантических. Еще есть такая штука, как Cross-Attention, которая связывает энкодер и декодер, позволяя декодеру “запрашивать” у закодированного входного текста релевантную информацию для генерации ответа.

Архитектура механизма внимания в архитектурах ИИ-трансформеров. Источник: .
Encoder и Decoder в трансформере: как устроен мозг модели
Хотя изначальный трансформер использовал и энкодер, и декодер, современные модели часто применяют только одну из этих частей, а выбор этой части уже определяет специализацию нейросети.
- Encoder-only модели (например, BERT) идеальны для задач, связанных с пониманием языка. Энкодер принимает входной текст и создает его всестороннее, контекстуализированное представление для каждого токена. Он видит все слова сразу, что позволяет ему понять истинный смысл предложения. Такие модели блестяще справляются с классификацией текста, извлечением сущностей или семантическим поиском конкретных элементов.
- Decoder-only модели (например, GPT, LLaMA*, Qwen) — это архитектуры для генерации текста. Декодер работает авторегрессионно: он предсказывает следующее слово в последовательности, имея доступ только к предыдущим словам (это делается с помощью маскировки будущих токенов). Эти модели-декодеры стали must-have инструментом для написания текстов, программирования или простого чатинга с нейросетью.
- Encoder-Decoder модели (T5, BART) объединяют оба подхода. Энкодер обрабатывает входные данные (например, текст на английском), а декодер, используя механизм Cross-Attention, генерирует выходные данные (например, перевод на французском). Эта архитектура подходит для задач перевода, суммаризации и перефразирования текста, но сейчас такие модели не в ходу.

Как работают компоненты Encoder и Decoder в архитектуре ИИ-трансформеров. Источник: .
Самые известные трансформеры: BERT, GPT, LLaMA*, Qwen, Gemini
На базе архитектуры трансформеров вырос целых урожай семейств ИИ-моделей, которые определили современный ландшафт индустрии искусственного интеллекта.
- BERT (Google) — один из родоначальников движения ИИ-трансформеров, представляющий из себя энкодерную модель, которая научилась понимать глубокий контекст слов, предварительно обучаясь на задачах предсказания замаскированных токенов в предложении. Он стала основой для бесчисленных сервисов семантического поиска и анализа текста.
- GPT (OpenAI) — основополагатель decoder-only подхода. Его успех доказал, что масштабное предварительное обучение искусственного интеллекта на генерации следующего слова создает мощную универсальную языковую модель, которая может покорить весь мир.
- LLaMA* (Meta**) и Mistral (MistralAI) — это открытые и эффективные decoder-only архитектуры, которые одними из первых демократизировали доступ к мощным LLM, позволив запускать их на локальном оборудовании.
- Qwen (Alibaba) и Gemini (Google) — эволюционный этап перехода трансформеров в сторону мультимодальности и гибридности. Они используют особые вариации базовой архитектуры трансформеров для обработки не только текста, но и изображений, аудио и видео, часто комбинируя разные типы внимания и специализированные энкодеры.

Одни из самых топовых семейств ИИ-трансформеров в 2025 году. Источник: .
Как трансформеры изменили нейросети и породили LLM?
На архитектурном уровне модели трансформеров разительно отличаются от своих предшественников в лице RNN-моделей, однако если первые совершили настоящий фурор, то появление вторых для многих прошло без особых эмоций (если не считать времен выхода Apple Siri). Так как же трансформеры вызвали настолько бурную реакцию общественности и почему этот подход стал настолько фундаментальным?
Во-первых, архитектура работы механизма внимания трансформеров идеально подходит для вычислений на графических ускорителях благодаря их высочайшему параллелизму. Это позволило эффективно масштабировать модели-трансформеры, обучая их на триллионах токенов данных, не сталкиваясь с дикими тормозами как при обучении RNN-нейросетей. Впоследствии это привело к рождению феномена LLM-моделей с огромным количеством параметров.
Во-вторых, трансформеры оказались универсальными. Механизм внимания был настолько эффективен и у него было столько сценариев использования, что его успешно адаптировали для работы с изображениями (Vision Transformers), звуком (Audio Transformers) и другими модальностями данных.
В-третьих, у трансформеров просто не было достойных конкурентов — сравнивать их с устаревшими архитектурами CNN и RNN было глупо, а идея диффузионных архитектур была на этапе зародыша. Из-за этого все топовые IT-компании начали использовать архитектуру-трансформеров для создания своих семейств нейросетей, соревнуясь в точности, производительности, функционале, а со временем и в компактности.
Однако доминирование трансформеров не вечно. Квадратичная сложность вычислений токенов внимания по отношению к увеличению длины контекста подтолкнуло исследователей со всего мира к поиску новых, более эффективных ИИ-архитектур, в результате чего разработчики предложили подходы State-Space Models (Mamba) и Диффузионные LLM, которые либо заменяют механизм внимания, либо гибридизируют его с другими принципами работы нейросетей.
Выводы
Мы живем в эпоху ИИ-трансформеров, и она наглядно показывает, что внимание — это ключевой принцип восприятия информации не только для человека, но и для искусственного интеллекта. Эта архитектура буквально перевернула 2020-е годы с ног на голову, породив целую экосистему современных LLM и мультимодальных ассистентов, отодвинув другие направления развития IT-индустрии на второй план. Но несмотря на всю свою революционность, трансформеры не могли держаться на своем пьедестале вечно из-за своих непреодолимых ограничений, поэтому сейчас индустрия стоит на следующем витке эволюции, именуемым синергией разных архитектур. Вероятно, уже в ближайшем будущем мы увидим гибридные подходы, где эффективное обучение трансформеров сочетается с фундаментальной памятью моделей State-Space, генеративной мощью диффузионных нейросетей и сложной логикой графовых структур. Мы в ServerFlow будем внимательно следить за этим переходом и уже готовим новый цикл материалов, посвященный архитектурам будущего, которые определят облик ИИ в ближайшие годы. Эпоха трансформеров заложила невероятно прочный фундамент, и теперь настало время строить на нем новые, еще более удивительные технологии.
*LLAMA — проект Meta Platforms Inc.**, деятельность которой в России признана экстремистской и запрещена
**Деятельность Meta Platforms Inc. в России признана экстремистской и запрещена
