Что такое параметры модели: почему DeepSeek бывает на 7B, 70B и 405B
Введение
Если вы активно следите за новостями в мире ИИ, то наверняка видели вместе с названием нейросети приписку 3b, 7b, 70b, 671b и т.д. Многие могли бы подумать, что это просто очередное техническое обозначение, которое несет мало пользы для обычного юзера, но на самом деле за этими, казалось бы, бессмысленными префиксами, скрывается важнейшая характеристика той или иной ИИ-модели — объем параметров. И именно в этом объеме параметров скрывается вся суть нейросети, благодаря которой слово интеллект преобладает над словом искусственный. В этой статье специалисты компании ServerFlow расскажут вам, что такое параметры ИИ-моделей, почему они измеряются в миллиардах, зачем им так много памяти и как они влияют на локальный инференс ИИ.
Что такое параметры модели простыми словами
Представьте, что у вас есть искусственный мозг, который нужно научить отличать кошку от собаки. Вы показываете ему тысячи картинок, а он пытается уловить закономерности: уши, морду, хвост, текстуру шерсти. Чтобы все это запомнить, нейросети нужны внутренние настройки — и вот эти настройки и называются параметрами модели. Каждый параметр — это просто число, описывающее, насколько сильно один "нейрон" влияет на другой. Во время обучения модель корректирует эти числа, стараясь минимизировать количество ошибок.
Когда вы слышите, что у модели 7 миллиардов параметров, это означает, что внутри нее — 7 000 000 000 таких чисел, определяющих, как именно она думает, обобщает информацию и делает выводы. В каждом слое нейросети тысячи нейронов, и каждый соединен со многими другими — поэтому количество параметров растет лавинообразно. Одни нейроны отвечают за грамматику, другие — за смысл, а третьи — за связь между контекстами. Когда модель видит новое, ранее неизвестное ей предложение, она не запоминает его напрямую — она пропускает его через свои параметры и сравнивает с тем, что уже "знает", улавливая уже знакомые паттерны для понимания пользовательского запроса и генерации качественного ответа.
По сути, параметры — это воплощенный опыт модели. Как если бы человек мог хранить воспоминания не в виде картинок или чувств, а только зависимостями и бинарными связями, например: "кошка похожа на животное", "кошка не похожа на автомобиль".

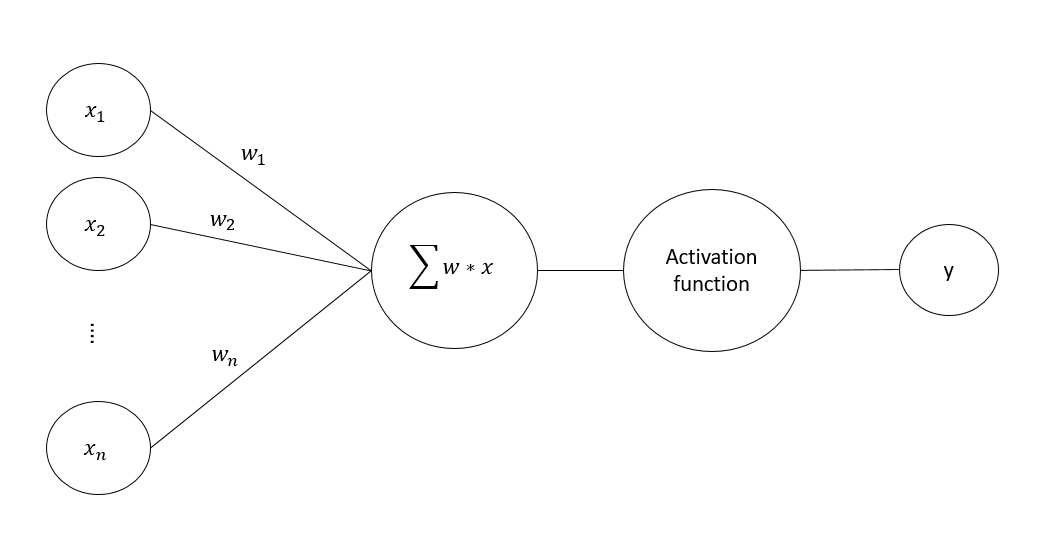
Веса, смещения (biases) и слои — все это и есть параметры нейросетей. Источник: .
Почему параметры измеряются миллиардами и что это дает
Теперь самое интересное: почему счет идет не в тысячах и даже не в миллионах, а в миллиардах параметров? Все просто — чем больше у модели слоев и связей, тем больше чисел нужно, чтобы описать ее внутреннее состояние. Каждый слой — как фильтр, который выделяет все более сложные зависимости. В первой "ступени" сеть замечает отдельные буквы или пиксели, во второй — слова и формы, а в десятой уже улавливает смысл. Чтобы достичь этого уровня абстракции, приходится использовать огромное количество параметров.
Именно поэтому мы видим такие обозначения:
- 3B — компактная модель, которая уже умеет писать тексты, отвечать на вопросы, выполнять базовые задачи, но быстро забывает, о чем шла речь в диалоге. Запустится даже на смартфоне.
- 7B — нейросеть уже уверенно оперирует более емким контекстом, понимает смысл, делает собственные выводы. Достаточно ПК с хорошей видюхой или мощного ноутбука.
- 70B — искусственный интеллект активно рассуждает, комбинирует факты, пишет тексты с "глубиной". Запуск требует нескольких графических ускорителей.
- 405B — LLM уже выходит за рамки буквального смысла, начинает анализировать намерения и подтексты. Для вывода понадобится полноценный GPU-сервер.
Другими словами, чем больше параметров имеет модель, тем богаче и сложнее структура ее мыслей — у искусственного интеллекта растут интеллектуальные способности.
Почему “больше” — не всегда значит “умнее”
И вот тут возникает логичный вопрос: “Если чем больше параметров — тем лучше, почему бы просто не сделать модель на триллион параметров и наслаждаться эффективностью искусственного интеллекта?”. Однако, здесь в ход идет очень важный фактор, который можно коротко и лаконично описать фразой “горе от ума”.
Конечно, иногда правда начинает казаться, что гонка за параметрами напоминает соревнование центральных процессоров по числу ядер. Но, как и в мире железа, количество — не всегда равно качество. Важнее то, как эти ядра (или параметры) взаимодействуют.
Большая модель не всегда лучше понимает контекст. Она может "захлебываться" от лишней информации, терять фокус и выдавать ответ, который вроде бы красивый, но совсем не точный, в то время как маленькие модели (7B, 13B) часто показывают блестящие результаты при выполнении узкоспециализированных задач — например, при анализе кода, написании текстов, общении или работе с ограниченным доменом знаний. Современные архитектуры, такие как Qwen, Baidu, GPT-OSS, Granite и другие доказывают: важнее не просто добавить параметры, а грамотно их распределить. Прорывная ИИ-модель GPT-3.5 имела внушительные для своего времени 175 миллиардов параметров, однако даже DeepSeek R1 с 70 миллиардов параметров обходит ее во всех задачах. Использование передовых технологий вроде "attention" и "mixture of experts" позволяет моделям с меньшим числом параметров работать почти на уровне гигантов с триллионами параметров.
Это прямо коррелирует с работой мозга человека: мы умны не потому что у нас много нейронов (в этом нас обходят черные дельфины), а потому что связь между этими нейронами очень сложна и отлично выстроена. Нейросеть с грамотно организованной архитектурой может использовать свои параметры эффективнее — как хорошо натренированный спортсмен, который тратит меньше энергии на упражнения, но достигает лучшего результата. Поэтому в ИИ-индустрии разработчики все чаще говорят не "у нас 900 миллиардов параметров", а "у нас новая архитектура, которая использует параметры в 5 раз эффективнее". Так что количество параметров — не равно интеллект. Иногда меньше действительно значит лучше.

Некоторые разработчики ИИ не следуют тенденциям индустрии и продолжают выпускать LLM с триллионами параметров, и несмотря на их эффективность, их никто не скачивает, ведь для запуска таких ИИ необходимо 2 ТБ VRAM. Яркий пример таких LLM — Ling-1T от дочерней компании Alibaba InclusionAI. Вот к чему приводит мышление “Больше — значит лучше”. Источник: .
Что из себя представляют параметры и почему они требуют много памяти
Каждый параметр — это не просто логическая единица, а реальное число, хранящееся в памяти компьютера. Обычно это 16-битное (float16) или 8-битное (int8) значение. И когда таких чисел миллиарды, они требуют колоссальных ресурсов.
Посчитаем грубо и без тонкостей:
- 7 миллиардов параметров занимают около 14 ГБ памяти.
- 70 миллиардов параметров — уже около 140 ГБ.
- А 405 миллиардов параметров — 810 ГБ только под веса!

Формула подсчета потребляемой VRAM для 7b модели.
Вот почему для инференса больших языковых моделей нужны ИИ-ускорителей с 80-141 ГБ VRAM, объединенные в кластеры с помощью NVLink или Infinity Fabric. Современные GPU вроде NVIDIA GB300 или AMD Instinct MI355X позволяют объединять память и вычислительные мощности, работая как единое целое, чтобы модель могла поместиться целиком в видеопамять и эффективно использовать ее.
Чем больше параметров, тем больше гигабайт для ее хранения нужно, и тем важнее становится правильно спроектированная серверная инфраструктура. Вот почему мы в ServerFlow уделяем так много внимания конфигурации железа под нейросети: от распределения GPU по слотам до пропускной способности NVLink и энергопитания. Без надежной инфраструктуры даже самая умная модель останется набором чисел, которые негде хранить и не на чем запустить.
Как параметры влияют на инференс
Когда ИИ-модель работает, например, отвечает на запрос, пишет текст, решает задачу или создает код, она не обучается заново. Все миллиарды параметров остаются неизменными. В момент инференса нейросеть просто использует их, чтобы вычислить, какое слово, число, буква или токен идет следующим. Нейросеть будто открывает внутреннюю библиотеку из параметров, выбирая те, которые ей нужны, и после этого воспроизводит их, причем, всего за пару секунд. Она не придумывает ответ с нуля, а извлекает закономерности, похожие на то, что уже видела при обучении. Вот почему производительность при инференсе зависит не только от числа параметров, но и от скорости доступа к памяти. Механизмы вроде KV-Cache или FlashAttention позволяют не пересчитывать лишние куски контекста, ускоряя инференс нейросети в разы и экономя огромное количество памяти.
Подведем итог: параметры — это библиотека знаний, а инференс — это скорость поиска нужной книги. Чем больше книг, тем богаче знания, но тем сложнее найти нужную книгу, поэтому крайне важно организовать быстрый поиск.
.jpg "Инференс DeepSeek R1 на смартфоне")
Компактные современные нейросети с небольшим количеством параметров можно запускать даже на смартфонах, сохраняя высокий уровень эффективности.
Выводы
Теперь можно взглянуть на все под другим углом. Параметры модели — это ее опыт, ее фундаментальные знания. Каждый параметр хранит крошечный фрагмент информации, миллиарды которых вместе складываются в единый интеллект. Когда мы говорим, что модель имеет 3, 32 или 322 миллиарда параметров, мы фактически говорим о масштабе ее памяти и способности понимать мир. Но создать модель — значит не просто написать код, запихнув в нее терабайты информации, а построить инфраструктуру, которая выдержит миллиарды чисел, миллионы операций в секунду и огромные массивы данных, при этом сможет эффективно перебирать их при запросе. Вот почему ServerFlow говорит о параметрах не как о цифрах, а как о нагрузке, архитектуре и мощности. Мы знаем, какое железо позволит модели думать быстрее, хранить больше и отвечать умнее. В блоге ServerFlow вы найдете больше материалов о том, как работают нейросети изнутри — о токенах, KV-Cache, FlashAttention и о железе, которое заставляет все это работать в реальном времени.
