Унифицированная память — что это такое и почему на ней держатся все ИИ-ПК
Введение
Компактные ИИ-ПК — это настоящий тренд последних нескольких лет. Сама возможность запускать современные 100b нейронки на устройствах, умещающихся буквально в углу рабочего стола, взорвала головы ИИ-энтузиастам, ведь раньше подобные махинации были доступны только счастливым обладателям полноценных серверных или, в крайнем случае, профессиональных GPU. Но как на небольшой коробочке, уступающей по размерам даже потребительским NAS, не говоря уже о полноценных ПК, удается запускать полноразмерные LLM без жесткой квантизации или каких-то архитектурных ухищрений? Все благодаря технологии унифицированной памяти (Unified Memory). В этой статье специалисты компании ServerFlow расскажут вам, что из себя представляет унифицированная память, как она появилась и впервые была задействована, сравним ее с классической дискретной памятью, а также объясним, какие амбассадоры Unified Memory существуют на рынке на данный момент.
Что такое унифицированная память?
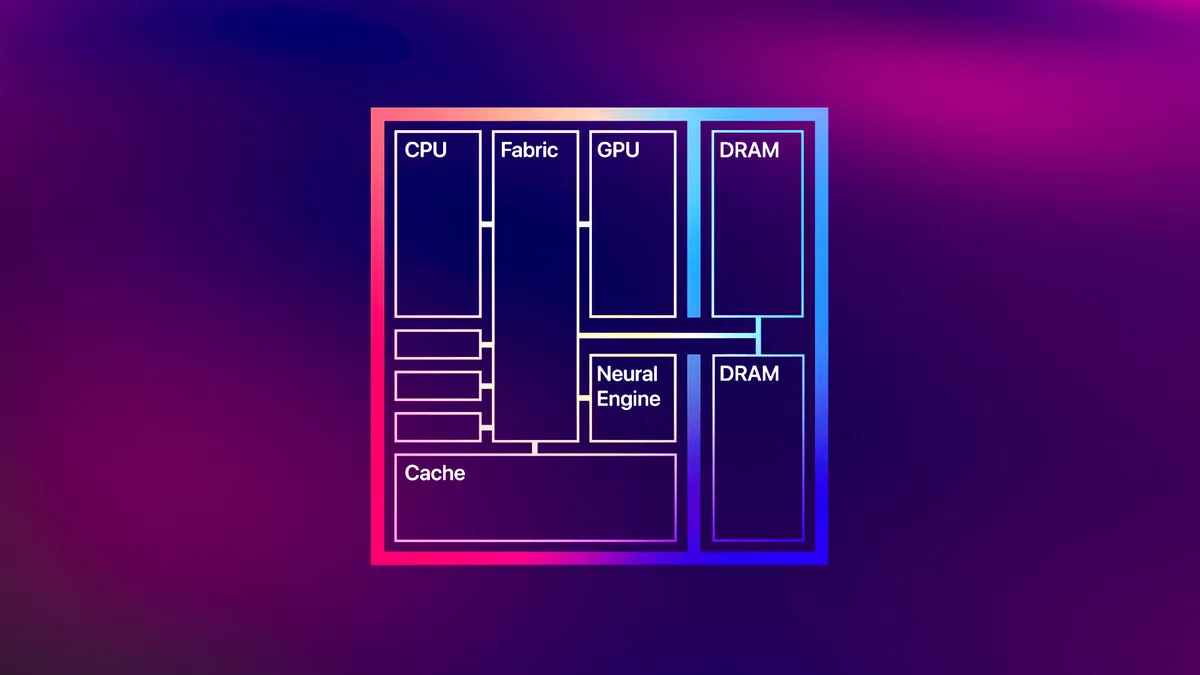
Если не вдаваться в супер-пупер сложную инженерную терминологию, то унифицированная память (Unified Memory) — это, по сути, архитектура использования системной оперативной памяти, при которой сразу все вычислительные компоненты имеют к ней доступ и могут применять ее ресурсы для выполнения своих специализированных задач. То есть, и CPU и GPU и NPU могут одновременно пользоваться одной и той же физической памятью, видят одни и те же данные и не нуждаются в копировании информации из одного пула в другой.
Пока не особо понятно, да? Давайте объясним на примере классической, дискретной памяти. Скорее всего, у вас есть ПК, с высокой долей вероятности в нем стоит какая-никакая видюха и оперативка. В вашем ПК центральный процессор имеет прямой доступ только к оперативной памяти, а графический процессор имеет доступ только к своей видеопамяти. И вот вы решили заинференсить нейронку на своей топовой сборочке, но возникает дилемма: когда нейросеть хочет что-то посчитать на видеокарте, драйвер должен сначала скопировать данные из RAM в VRAM, а после вычислений — забрать результат обратно. И этот процесс происходит постоянно, каждый раз при инференсе локальной модели. Это постоянное перетягивание данных через шину PCI Express съедает и время (возникают задержки), и энергию (растет энергопотребление), и, что самое обидное, ограничивает размер модели объемом именно видеопамяти, так как RAM и VRAM обособлены друг от друга. Если у вас видеокарта на 16 ГБ, вы просто не загрузите модель, весящую 20 ГБ, даже если оперативной памяти у вас 128 ГБ.
Унифицированная память решает все эти проблемы не самым элегантным, зато очень действенным способом — просто лепит всю память в одну кучу. Все вычислительные ядра CPU, GPU и NPU получают один общий, но зато очень большой пул физической памяти (LPDDR или, что более редко, DDR). Чипам больше не нужно постоянно играть в горячую картошку с данными — когда процессору нужно использовать ресурсы памяти, они просто берут их без лишних действий, поэтому задержки сводятся к минимуму, а TDP не растет по экспоненте. При этом, вы можете вручную настроить, сколько памяти достанется тому или иному чипу: хотите, чтобы GPU достались все 128 ГБ, а CPU оставить на голодном пайке? Всегда пожалуйста! Такая опция есть в BIOS всех систем, исповедующих концепцию унифицированной памяти.

Сравнение архитектуры унифицированной памяти и традиционной памяти. Источник: .
Как появилась концепция унифицированной памяти
Сама идея далеко не нова: инженеры мечтали о едином адресном пространстве для CPU и GPU еще в девяностых, но упирались в ограничения техпроцессов и себестоимости ее использования. Первыми шагами к унификации стали интегрированные графические процессоры от Intel и AMD. Например, во встройке Intel HD часть медленной системной оперативной памяти просто “откусывалась” под нужды видеокарты. Эта технология называлось Shared Memory (общая память) и сильно замедляло систему, так как DDR была слишком медленной для работы с графикой.
Затем развитие концепции унифицированной памяти продолжилось на неожиданном фронте — игровых консолях ранних 2010-х. PlayStation 4 и Xbox One использовали единый пул быстрой памяти GDDR5 объемом 8 ГБ, доступный и процессорным, и графическим ядрам. По началу все подумали, что в офисах Sony и Microsoft употребляют что-то очень забористое, раз уж они додумались подключить CPU к VRAM, однако когда дело коснулось консольных энтузиастов, все по достоинству оценили преимущества унифицированной памяти — задержки сводились к абсолютному минимуму, игры и программы летали как скоростные джеты. Однако для ПК эта концепция все еще оставалась экзотикой.
Затем к движухе подключилась Nvidia, представив программную технологию CUDA Unified Memory. Она позволила разработчикам писать код так, будто у CPU и GPU общая память, но на физическом уровне данные все равно копировались по шине PCIe. CUDA Unified Memory была лишь пародией на настоящую Unified Memory, и была сделана скорее для удобства программистов ядер, так как на задержки эта система никак не влияла.
Переломным моментом для массового рынка стал выход процессоров Apple Silicon M1 в 2020 году. Apple, вооружившись опытом создания мобильных чипов серии A, спроектировала SoC-чип, где восемь (а позже и больше) ядер CPU, мощный GPU и NPU-движок работали с одним пулом LPDDR4X/LPDDR5 памяти, физически распаянной на общей подложке с вычислительными компонентами. Ширина шины памяти достигала 128-512 бит в зависимости от модели, а пропускная способность доходила до 400-800 ГБ/с — цифры, которыми тогда могли похвастаться только дискретные GPU. Сначала Apple использовала унифицированную память как маркетинговую побрякушку и оснащала свои MacBook Air и Mac Mini лишь 16 ГБ общего пула. Однако когда компания поняла, что на этом можно мощно заработать, вышли чипы M2 Ultra, на базе которых вышли первые в индустрии ИИ-ПК Apple Mac Studio и Apple Mac Pro со 192 ГБ унифицированной памяти. Да-да, ни Nvidia, ни AMD, ни даже Intel, а Apple придумала саму концепцию компактных ИИ-станций с унифицированной памятью.
Дальше к иннициативе снова подключились Intel и AMD — первая использовала память в Meteor Lake и Lunar Lake, а вторая применяла унифицированный пул в линейке Ryzen AI. А потом подоспела и Nvidia, которая сначала применяла Unified Memory в системах серии Jetson для периферии, потом выпустила суперчипы GH200/GB200 c общим пулом памяти HBM3/HBM3E и LPDDR5X, а затем и выпустила свой компактный магнум-опус в лице DGX Spark, на который активно покушается AMD с грядущими Halo Box. Интересно, что Nvidia первой вывела унифицированную память в корпоративный сегмент, объединив, казалось бы, несовместимые виды памяти за счет своего проприетарного интерконнекта NVLink C2C, по сути открыв новый способ использования Unified Memory, который до сих пор никто не повторил.
Унифицированная vs дискретная память
Если вы до сих пор не поняли, почему унифицированная память на голову лучше дискретной памяти, мы добьем ваши сомнения, напрямую сравнив два типа архитектур оперативки лоб в лоб:
- Общий пул. В дискретной системе вы ограничены фиксированным объемом видеопамяти. Купили карту с 24 ГБ — хоть в лепешку расшибиться, модель на 30 ГБ не запустится, даже если системной памяти 128 ГБ и она свободна. Унифицированная архитектура позволяет выделить под нужды GPU или NPU практически всю доступную RAM (конечно, за вычетом того, что занято ОС и приложениями). Если у вас 128 ГБ на борту, вы можете выделить 64 ГБ под модель, чего достаточно для инференса топовых нейронок с 70+ миллиардов параметров. Это решающий фактор для локального запуска LLM на компактных ИИ-ПК.
- Пропускная способность. Здесь картина сложнее. Топовые дискретные GPU используют специализированную память вроде HBM, скорость которых исчисляется в терабайтах в секунду. Унифицированная память на базе LPDDR5X может достигать 400-800 ГБ/с. Этого достаточно для большинства задач инференса, но все же меньше, чем у профессиональных и уж тем более дата-центровых флагманов GPU. Для обучения больших моделей высокая пропускная способность критична, но для инференса важнее объем. К тому же унифицированная архитектура избавлена от задержек копирования через PCIe, что частично компенсирует пониженную скорость.
- Энергоэффективность. Каждый лишний акт копирования данных между чипами стоит энергии. Дискретные системы вынуждены гонять данные по длинным линиям PCIe на материнской плате. Унифицированная память требует куда меньше энергии на перемещение данных, особенно при распайке рядом с чипом.
- Стоимость и гибкость. Дискретные системы позволяют наращивать память и менять видеокарту по отдельности, что удобно для ИИ-энтузиастов или серверного сегмента, где нагрузки постоянно масштабируются. Унифицированные платформы почти всегда идут с распаянной памятью, которую нельзя увеличить.
- Программная модель. Унифицированная память — настоящий подарок для разработчиков. Вместо того чтобы управлять копированием данных между хостом и устройством (как в CUDA с cudaMemcpy), можно просто выделить буфер один раз и использовать его в любых контекстах, что невероятно удобно.
Кто использует унифицированную память
Сегодня унифицированная память — это не экзотика, а стандарт де-факто для любого устройства, претендующего на звание ИИ-оборудования.
- Nvidia — продолжает применять унифицированную память LPDDR5/X в системах серии Jetson Orin и Nano, а также во всех суперчипах для корпоративного сегмента, от Grace Hopper до Vera Rubin. Однако наиболее известным представителем концепции Unified Memory в ассортименте Nvidia, конечно же, является компактный ИИ-ПК DGX Spark на базе чипа GB10, где CPU Grace и GPU Blackwell работают с единым пулом в 128 ГБ памяти LPDDR5X, что позволяет запускать крупные LLM объемом до 120B.

Nvidia DGX Spark. Источник: .
- AMD — Unified Memory оснащаются APU-процессоры линейки Ryzen AI, наиболее актуальными из которых являются передовые Ryzen AI Max+ 395, совмещающие процессор Zen 5, графику RDNA 3.5 и NPU XDNA2. Грядущие ИИ-боксы на базе этих чипов получат до 128 ГБ общей памяти LPDDR5X с возможностью выделения до 64 ГБ для GPU. AMD также анонсировала следующее поколение процессоров Ryzen AI Max+ 400, которые принесут поддержку колоссального пула унифицированной памяти до 192 ГБ с возможностью выделения до 160 ГБ для GPU.

AMD Halo Box. Источник: .
- Apple — пропихивает Unified Memory во все свои десктопные и профессиональные SoC-чипы линеек Pro/Max/Ultra. Например, ранее в Apple Mac Studio на базе процессоров M3 Ultra было доступно до 192 ГБ общей памяти LPDDR5, что позволяло инференсить огромные нейронки, если они поддерживались ПО-сэком Metal. Однако из-за дефицита памяти, Apple урезала конфигурации своей станции, оставив версии Mac Studio лишь на 92 ГБ, чего явно не хватает для конкуренции с другими ИИ-ПК.

Apple Mac Studio и Mac Mini. Источник: .
Выводы
Как мы выяснили, унифицированная память — это чуть ли не самый главный компонент современных домашних инференс-станций, ведь именно она решила фундаментальные проблемы логического вывода LLM на потребительских устройствах: высокую задержку и нехватку VRAM. Конечно, унифицированная память не лишена недостатков: распаянные чипы ограничивают апгрейд, а пропускная способность пока уступает топовым дискретным решениям. Но тренд очевиден: с каждым поколением растет и скорость (LPDDR6 не за горами), и объем, и эффективность. Уже сегодня все основные игроки сделали ставку на эту архитектуру, и именно на ней будут строиться ИИ-ПК следующего поколения. Так что если вы присматриваете себе решение для экспериментов с нейросетями, смотрите не только на бренд GPU, но и на наличие Unified Memory.
