RDMA — что это такое и как оно работает?
Введение
Кластерные системы становятся основой всех вычислительных инфраструктур, особенно в таких областях, как HPC и ИИ. Однако, чтобы серверы, входящие в кластер, могли эффективно взаимодействовать друг с другом, важно обеспечить прямой доступ к данным без необходимости в обращении к CPU, чтобы не замедлять работу системы и снизить нагрузку процессоров для выполнения более важных задач. Именно такой функцией обладает технология RDMA (Remote Direct Memory Access). В этой статье мы рассмотрим, что такое технология RDMA, какие вариации RDMA существуют и перечислим компании, которые выпускают оборудование с поддержкой этой инновационной функции.
Саммари
Поскольку тема RDMA-технологий крайне многогранна, для более простого усвоения материала делимся с вами картой таблицей со сравнением основных и альтернативных протоколов прямого подключения к памяти.
|
Характеристика |
InfiniBand |
RoCE |
iWARP |
Omni-Path |
Onload |
|
Тип сети |
Проприетарная |
Ethernet (Lossless) |
Ethernet (любой) |
Проприетарная |
Ethernet (любой) |
|
Задержка |
<1 мкс |
2–5 мкс |
10–50 мкс |
<1 мкс |
<1 мкс |
|
Пропускная способность |
800 Гбит/с |
800 Гбит/с |
200 Гбит/с |
100 Гбит/с |
Ограничена CPU/сетью |
|
Требования к оборудованию |
Адаптеры InfiniBand |
Адаптеры с RoCE |
Адаптеры с iWARP |
Адаптеры Omni-Path |
Стандартные NIC |
|
Протокол передачи |
Собственный стек |
UDP/IP (RoCEv2) |
TCP/IP |
Собственный стек |
TCP/IP (оптимизация) |
|
Совместимость |
Только InfiniBand |
Ethernet с PFC/ECN |
Любой Ethernet |
Только Omni-Path |
Только AMD |
|
Основные производители |
Nvidia (Mellanox) |
Nvidia, Broadcom |
Intel, Marvell |
Intel/Cornelis |
AMD (Xilinx/Solarflare) |
Что такое RDMA?
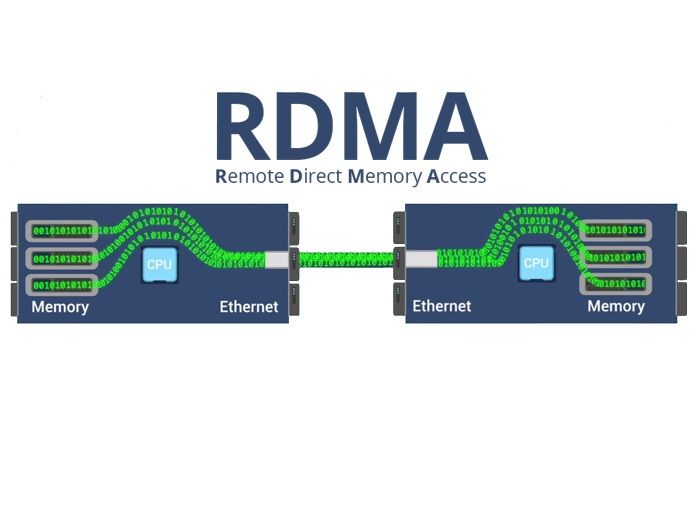
RDMA — это обобщающий термин для ряда технологий, которые обеспечивают прямой доступ к памяти одного устройства к другому в рамках одной вычислительной инфраструктуры, при этом минуя обращение к центральному процессору и операционной системе. Использование RDMA-технологий значительно снижает задержки и нагрузку на ЦП, что крайне важно для работы высокопроизводительных приложений и ИИ-ориентированных инфраструктур. Технологии RDMA поддерживаются специальными сетевыми картами (Smart NIC), которые берут на себя рутинные операции с передачей и обработкой данных, тем самым разгружая CPU (этот процесс называется Offloading). Умные сетевые карты могут самостоятельно обращаться к оперативной памяти системы, копировать и добавлять новые данные. Без использования Smart NIC данные будут дополнительно копироваться в буферы операционной системы, что задействует свободные такты процессора. В случаях с малоядерными CPU, 6 из 8 ядер процессора могут быть заняты исключительно копированием данных и ресурсов системы не будет хватать для выполнения других операций, даже если вы выстроили мощную вычислительную инфраструктуру.

Визуализация обхода ядра операционной системы с помощью RDMA-совместимой сетевой карты. Источник: .
Разновидности RDMA
Как было сказано выше, RDMA — это не единая технология, а целый ряд разных по реализации технологий, обеспечивающих прямой доступ к памяти. Поскольку все нижеперечисленные вариации RDMA настолько сложны и многогранны, в будущем мы посвятим для каждого протокола по отдельной статье, а сейчас коротко рассмотрим их особенности.
InfiniBand
InfiniBand — это специализированный протокол, разработанный в 1999 году исключительно для наиболее высокопроизводительных инфраструктур. Infiniband использует собственную экосистему устройств, которая включает в себя специальные коммутаторы, кабели и сетевые карты. Вопреки распространенному мнению, несмотря на архитектурное сходство сетевого оборудования, протокол InfiniBand не имеет ничего общего с Ethernet и является полностью проприетарной разработкой. Благодаря использованию Infiniband, пропускная способность внутри вычислительных инфраструктур может достигать 800 Гбит/с, а задержки снижаются до 1 микросекунды (в 10 раз меньше минимальных задержек Ethernet), что повлияло на популяризацию этого протокола в секторе суперкомпьютеров и кластеров для машинного обучения. Ввиду того, что протокол Infiniband требует полной перестройки сетевой инфраструктуры, для владельцев коммерческих вычислительных систем интеграция Infiniband становится крайне дорогостоящей и, как следствие, недоступной.

Стек протоколов технологии InfiniBand. Источник: .
RoCE
RoCE (RDMA over Converged Ethernet) — это компромисс между высочайшей пропускной способностью InfiniBand и гибкостью Ethernet. RoCE позволяет использовать RDMA в стандартных Ethernet-сетях, что значительно снижает затраты на построение вычислительной инфраструктуры, поскольку владельцам не нужно покупать отдельное оборудование для поддержки протокола. Существует две основные версии протокола RoCE:
- RoCE v1, работающий в пределах одного Layer 2-домена.
- RoCE v2, поддерживающий маршрутизацию через IPv4/IPv6. Для RoCE v2 требуется настройка Lossless Ethernet с такими функциями, как Priority Flow Control (PFC) и Enhanced Transmission Selection (ETS), чтобы избежать потерь пакетов. Примечательно, что поддержка вышеперечисленных функций есть далеко не у всех коммутаторов, вследствие чего для поддержки этой вариации RoCE может потребоваться некоторая модернизация вычислительной инфраструктуры.

Схема работы протоколов RoCE v1 и RoCE v2. Источник: .
RoCE активно применяется в облачных платформах (Microsoft Azure, Alibaba Cloud) и распределенных базах данных (Oracle Exadata), поскольку в таких инфраструктурах крайне важно сохранять баланс между производительностью и совместимостью с традиционным Ethernet-оборудованием.
iWARP
iWARP (Internet Wide Area RDMA Protocol) — это протокол, реализующий функции RDMA поверх стека сетевых протоколов TCP/IP. В отличие от RoCE, он не требует Ethernet-коммутаторов типа Lossless Ethernet, что упрощает интеграцию в действующие сети, включая глобальные (WAN). iWARP подходит для корпоративных сред со смешанным оборудованием, где основополагающей ценностью является совместимость, а не экстремальная производительность. По сути, главной ценностью iWARP является то, что для интеграции этого протокола в вычислительную инфраструктуру, вам не требуется менять какое-либо оборудование. Ввиду этого, iWARP часто используют в устаревших системах или приложениях, где нельзя модернизировать сеть под InfiniBand или RoCE.

Схема получения прямого доступа к памяти с помощью протокола iWARP. Источник: .
Альтернативные реализации RDMA
Помимо трех основных реализаций прямого доступа к памяти, существует еще два интересных аналога RDMA, которые по разным причинам не пользуются большой популярностью.
Onload
Onload — это технология оптимизации сетевых операций, разработанная компанией Solarflare (ныне часть Xilinx/AMD). Принцип Onload заключается в том, что операции обработки данных выполняются как центральным процессором, так и специализированными сетевыми картами и программными алгоритмами, которые оптимизируют этот процесс, ускоряя работу протоколов TCP/IP для обхода ядра операционной системы, что отличает Onload от традиционного оффлоадинга. При этом Onload обеспечивает больший показатель задержки, чем основные реализации технологий RDMA, а также увеличивает нагрузку на CPU. Как и в случае с RoCE и iWARP, метод Onload часто используется в средах, где важна совместимость с существующими Ethernet-сетями, но требуется уменьшение задержек за счет оптимизации ПО, например, в веб-серверах или облачных приложениях. Примечательно, что при использовании Onload в Java-приложениях, задержки при передаче данных могут уменьшиться с 1 микросекунды до 1 миллисекунды за счет программной оптимизации.

Описание технологии прямого доступа к памяти Onload от Solarflare (AMD). Источник: .
Omni-Path
Omni-Path (ранее Intel Omni-Path) — это высокопроизводительная сетевая архитектура, разработанная компанией Intel для задач HPC и искусственного интеллекта. Она обеспечивает скорость до 100 Гбит/с, задержки менее 1 микросекунды и масштабируемость до 16 000 узлов. Как и InfiniBand, Omni-Path использует собственный сетевой протокол OpenFabrics (OFI), а также требует интеграции проприетарных кабелей и коммутаторов. Примечательно, что в архитектуре Intel Omni-Path процессор и сетевая карта соединены через интерфейс PCIe. Кроме того, сетевые карты с поддержкой Omni-Path были совместимы только с центральными процессорами Intel Xeon и Xeon Phi, что значительно ограничивало архитектурную гибкость в выстраивании вычислительных систем. Ключевые особенности Omni-Path включают аппаратное исправление ошибок без увеличения задержки и оптимизацию трафика для смешанных рабочих нагрузок. В настоящее время реализация технологии Omni-Path от Intel прекратила свое существование, однако наработки этого метода прямого подключения к памяти в настоящее время используются стартапом Cornelis Networks, главой которого является бывший вице-президент Intel Лиза Спелман, разрабатывая собственные протоколы для сектора HPC.

Обычный серверный процессор Intel Xeon и центральный процессор Intel Xeon с Omni-Path-совместимостью. Источник: .
Специализации технологий RDMA
Технологии RDMA делятся не только на разновидности, но и на несколько специализаций, которые отличаются обращением к разным типам памяти и в рамках разных вычислительных инфраструктур. Рассмотрим каждую из них по-отдельности.
GPU Direct RDMA
GPU Direct RDMA — технология компании Nvidia, которая позволяет умным сетевым картам (или DPU) напрямую обращаться к графической памяти GPU для чтения или записи данных, минуя обращение к центральному процессору. Умные сетевые карты, такие как Mellanox ConnectX с поддержкой InfiniBand или RoCE, используют адресные таблицы GPU (ATS) для отображения виртуальной памяти GPU (VRAM) в свое адресное пространство, передавая данные через PCIe или NVLink между графическими процессорами внутри узла, обеспечивая пропускную способность до 800 Гбит/с. Управление доступом к данным координируется через интерфейс PeerDirect API, который интегрирует драйверы CUDA и сетевых адаптеров.

Схема работы технологии GPU Direct RDMA. Источник: .
NVMe-oF RDMA
RDMA NVMe — комбинация технологий RDMA и NVMe-oF (NVMe over Fabrics), обеспечивающая прямой доступ к удаленным SSD-накопителям через сеть. RDMA позволяет передавать данные между памятью клиента и NVMe-устройством на сервере, при этом не задействуя центральный процессор. Например, в распределенных хранилищах (Ceph, DAOS) запрос на чтение данных обрабатывается сетевой картой сервера, которая копирует информацию напрямую из NVMe SSD в память клиента через протоколы RoCE или iWARP. Программные оптимизации, такие как Zero-Copy (исключение копирования в буферы ОС) и Multi-PDU (агрегация запросов), снижают накладные расходы при выстраивании систем, делая технологию полезной для таких сфер, как обработка больших данных и видеоаналитика, где требуются минимальные задержки и высокая пропускная способность.

Схема работы системы NVMe-oF, которая совместима с системами RDMA. Источник: .
MPI
MPI (Message Passing Interface) — специальный стандарт для обмена сообщениями в HPC-кластерах, где современные реализации (OpenMPI, Intel MPI) используют RDMA для ускорения передачи данных. Различные операции с данными выполняются через транспортные слои на основе RDMA (UCX, Verbs), что позволяет напрямую копировать данные между памятью узлов без участия CPU. Интеграция с UCX исключает зависимость от определенного типа оборудования, позволяя MPI работать поверх любых RDMA-сетей (InfiniBand, RoCE). Применение стандарта MPI ориентировано исключительно на сектор HPC и активно используется в суперкомпьютерах для сложнейших квантовых и химических вычислений, компьютерного моделирования новых материалов и обучения LLM.

Схема работы кластера на базе протокола MPI. Источник: .
Производители RDMA-оборудования
В настоящее время на рынке представлено 6 основных компаний, которые занимаются производством RDMA-совместимого оборудования:
- Nvidia (Mellanox) — компания Mellanox, которая ныне является частью Nvidia, производит SmartNIC серии ConnectX, а также коммутаторы Quantum и Spectrum (800 Gb/s) с поддержкой протоколов Infiniband и RoCE.
- Broadcom — производит полный цикл RDMA-решений на базе протокола RoCE, включая сетевые карты (400 Gb/s), коммутаторы серий Trident и Tomahawk.
- Intel — производит сетевые карты серии E810 и E830 (в планах решения до 200 Gb/s) с поддержкой протоколов iWARP, RoCEv2.
- Marvell — производит сетевые карты линейки FastLinQ 100 Gb/s с поддержкой двух основных реализаций на базе Ethernet, а также чипы для коммутаторов Prestera CX 8500.
- Cisco — производит коммутаторы серии Nexus 9000, которые широко используются в дата-центрах и стали основным стандартом в среде корпоративных RDMA-решений.
- Arista — выпускает RDMA-решения линейки 7060X5 на базе чипов Broadcom Tomahawk
Выводы
Технологии RDMA сыграли ключевую роль в развитии кластерных вычислительных инфраструктур, открыв совершенно новые возможности масштабирования производительности и минимизации задержек. Если ранее для формирования кластеров приходилось буквально с нуля разрабатывать собственные проприетарные технологии, вследствие чего такие системы могли себе позволить только крупнейшие компании, то благодаря появлению RDMA даже частные организации стали создавать собственные кластерные вычислительные системы. Это не только расширило возможности отдельных пользователей, но и во многом повлияло на развитие всей IT-индустрии, поскольку ныне даже небольшие стартапы могут использовать мощные вычислительные кластеры для разработки инновационных продуктов, таких как новые языковые модели и передовые сервисы.
