LoRA и QLoRA: как дообучить большую модель на одной видеокарте
Введение
Полное дообучение больших языковых моделей с помощью технологии Fine-Tuning совсем недавно было привилегией крупнейших корпораций, вроде OpenAI, Microsoft, Google и других акул ИИ-рынка. Такая приватность Fine-Tuning обуславливалась колоссальными требованиями к системным ресурсам — небольшие бизнес-стартапы вряд ли могли бы себе позволить разместить десятки мощных ИИ-ускорителей и оплачивать огромные счета за электроэнергию лишь для того, чтобы научить чат-бота отвечать клиентам с использованием корпоративных терминов. Но ситуация кардинально изменилась с приходом методов эффективной параметрической тонкой настройки (Parameter-Efficient Fine-Tuning, PEFT). Эти подходы позволяют адаптировать модель под конкретную задачу, обучая лишь крошечную часть ее параметров и задействуя при этом лишь один GPU. Среди всех методов PEFT именно LoRA (Low-Rank Adaptation) и ее продвинутая версия QLoRA стали настоящим отраслевым стандартом в 2025 году, открыв массовый доступ к кастомизации LLM. В этой статье мы расскажем вам, что из себя представляют методы LoRA и QLoRA, в чем их преимущества в сравнении с другими PEFT-подходами, а также объясним, почему именно LoRA и QLoRA стали локомотивом демократизации тонкой настройки нейросетей.
Что такое LoRA: идея и принцип работы
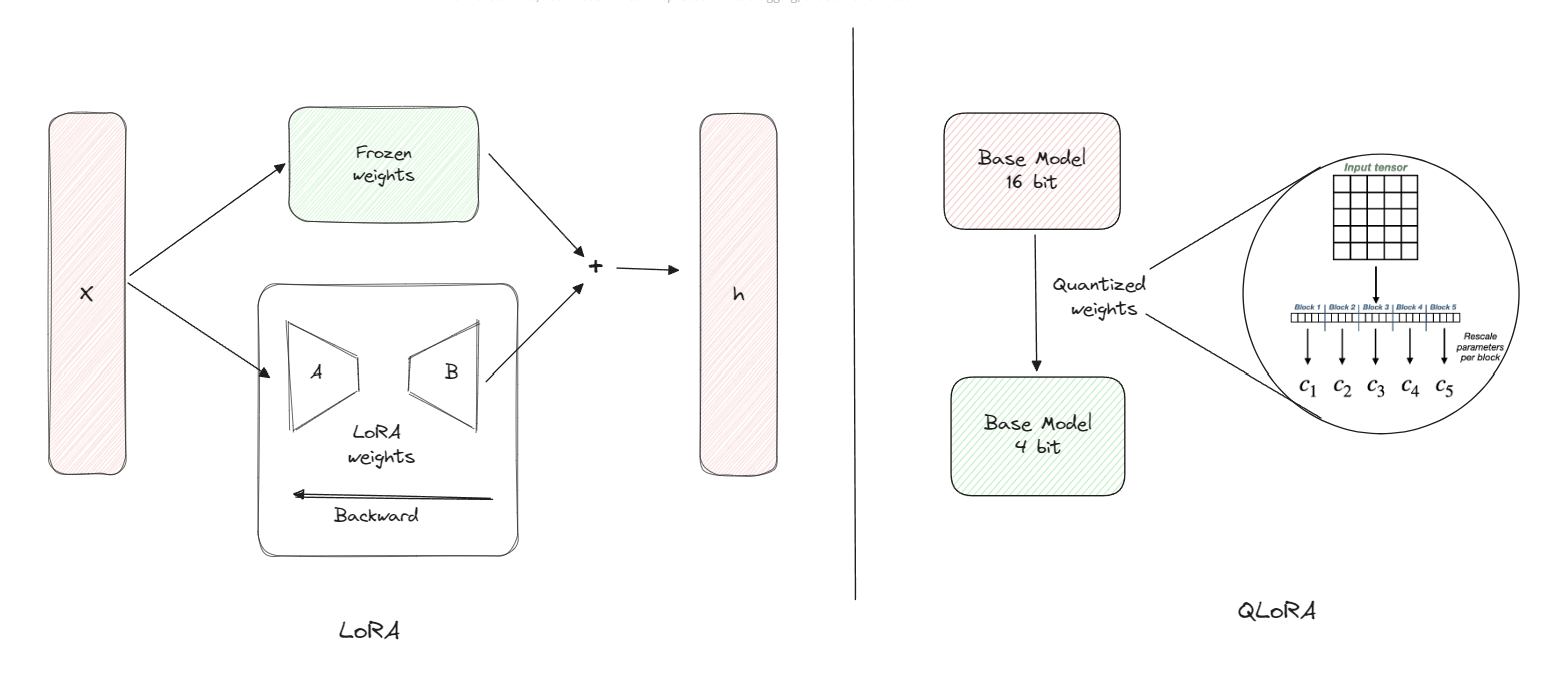
Идея использования LoRA моделей для кастомизации LLM одновременно и элегантна, и проста. Дело в том, что LoRA берет большую языковую модель не как интеллектуальную основу, а как базу знаний, которая становится костяком для дальнейшего дообучения. Вместо того, чтобы с нуля переписывать миллионы и миллиарды внутренних параметров, LoRA предлагает обучать небольшие “адаптеры” — дополнительные низкоранговые матрицы, которые интегрируют в нейросеть новые данные и вносят точечные корректировки в работу модели. Такой подход дает два ключевых преимущества:
- Снижение потребления видеопамяти (VRAM): поскольку обучается лишь малая доля параметров (часто менее 1%), исчезает необходимость хранить в памяти тяжелые оптимизаторы и градиенты для всех весов модели. Например, дообучение 7-миллиардной модели LLaMA с помощью LoRA легко укладывается в ресурсы одной потребительской видеокарты с 24 ГБ памяти, в то время как ее полный fine-tuning потребовал бы нескольких карт уровня H100.
- Ускорение обучения: полное переобучение нейросети может занять недели или месяцы, в то время как замена небольшого количества параметров с использованием информации из корпоративной базы данных или других источников занимает считанные часы.
Другими словами, простота и удобство LoRA стали визитной карточкой PEFT-подходов для переобучения LLM под требования определенных компаний. Однако умельцы нашли способ сделать LoRA-метод еще более эффективным, добавив в него технологию квантования.

Схема работы метода оптимизации LLM LoRA. Источник: .
Что такое QLoRA и чем она отличается
QLoRA — это эволюция LoRA, которая выводит эффективность кастомизации нейросетей на новый уровень за счет комбинации двух техник: квантизации и низкоранговой адаптации. Суть метода в том, что исходные веса модели сначала сжимаются до 4-битного представления, что радикально уменьшает их объем в памяти. Однако сам процесс обучения адаптеров происходит в более высокоточном формате (обычно bfloat16), что сохраняет качество генерации ответов модели. Главное преимущество QLoRA — еще более скромные требования к VRAM. Если классическая LoRA позволяла работать с 7B-моделями, то QLoRA открыла возможность дообучать 13B и даже 70B модели на одной видеокарте с 24-40 ГБ памяти. Это сделало QLoRA полноценным корпоративным стандартом для локальной тонкого настройки, когда в распоряжении разработчика нет парка серверных GPU. Можно с уверенностью сказать, что QLoRA открыла эру персонализации LLM, где каждый пользователь может настроить нейросеть под любые требования.

Схема работы метода оптимизации LLM QLoRA. Источник: .
PEFT и другие методы
Как мы уже упоминали, LoRA и QLoRA — это лишь малая, но крайне значимая часть широкого семейства методов кастомизации LLM, известного как Parameter-Efficient Fine-Tuning (PEFT). Эти методы позволяют разными способами дообучать нейросети, не требуя огромного расхода системных ресурсов. Среди них таких методов можно выделить следующие технологии:
- Adapter Tuning: встраивает в архитектуру LLM-трансформеров небольшие дополнительные слои (адаптеры), которые обучаются под выполнение конкретных задач. Основные параметры модели при этом замораживаются и выступают в роли базы знаний.
- Prefix Tuning: добавляет в начало входной последовательности токенов обучаемые векторы (префикс), которые настраивают поведение модели и выходные токены под нужную задачу.
- Prompt Tuning: упрощенная версия Prefix Tuning, где также используются обучаемые промпты, но только на входном уровне без доработки выходных токенов.
- P-Tuning и P-Tuning v2: усовершенствованные методы настройки с помощью обучаемых промптов. P-Tuning v2, в отличие от первой версии, применяет промпты на всех слоях модели, что повышает ее эффективность для выполнения самых сложных задач.
- IA3 (Infused Adapter by Inhibiting and Amplifying Inner Activations): метод, который обучает векторы, масштабирующие внутренние активации токенов моделей с архитектурой MoE, что делает тонкую настройку еще более эффективной.
- BitFit: простой, но эффективный метод, при котором обучаются только параметры смещения (bias) в модели, а все остальные веса замораживаются под базу знаний.
- MAM Adapter и UniPELT: гибридные методы, которые комбинируют несколько техник PEFT (например, адаптеры и префикс-тюнинг) в единую систему для достижения максимальной производительности дообучения.
На практике выбор между LoRA, QLoRA и другими методами PEFT зависит от ограничений вашего оборудования, но несмотря на широкий выбор, именно LoRA и QLoRA остаются самыми востребованными и практичными методами PEFT на сегодня. Если вы мечетесь между выбором LoRA и QLoRA, то первый стоит использовать на более мощном железе для ускорения дообучения, тогда как второй подойдет для использования даже в системах с ограниченными ресурсами.
Практические примеры использования
Давайте рассмотрим несколько примеров практического использования LoRA и QLoRA, чтобы оценить преимущества этих передовых методов кастомизации LLM в реальных кейсах. Типичный сценарий — это дообучение модели Qwen на внутренней документации компании для создания ИИ-ассистента, который точно отвечает на вопросы сотрудников компании. Другой пример — адаптация открытой модели LLaMA* для русскоязычного чат-бота с помощью LoRA, что позволяет учесть специфику языка и культурного контекста. Также популярно использование LoRA-адаптеров для моделей типа DeepSeek с целью генерации программного кода с учетом архитектуры конкретных корпоративных приложений. Все эти сценарии, такие как чат-боты, системы для ответов на FAQ, инструменты для генерации документов и т.д., перестали быть рутиной для разработчиков с появлением ИИ-библиотек вроде Hugging Face PEFT.
Но важно понимать, что LoRA и QLoRA хоть и оптимизируют потребление системных ресурсов, но они не могут полностью устранить требования к VRAM. Многие думают, что мощной видюхи вроде RTX 5090 может с 32 ГБ VRAM может хватить, и это действительно так, но лишь для базовой кастомизации LLM. Чтобы сделать процесс настройки более стабильным, быстрым и эффективным, не отвлекаясь на компромиссы и использование костылей вроде чекпоинтов градиентов и постраничных оптимизаторов, лучше всего использовать более тяжелую артиллерию, вроде NVIDIA A100 с 40 или 80 ГБ HBM2e памяти — это откроет вам доступ к дообучению моделей с более чем 13 миллиардами параметров, не теряя качество генерации ответов и выполняя настройку в максйимально сжатые сроки. А если вы хотите работать с еще более крупными LLM, развертывая масштабные ИИ-экосистемы с использованием LoRA и QLoRA, то вам подойдет мощный ускоритель NVIDIA H200 NVL со 141 ГБ HBM3, с которым вы перестанете упираться в потолок VRAM. А купить полностью укомплектованные серверы на базе A100 или H200 NVL можно в компании ServerFlow. Наши опытные специалисты помогут вам подобрать конфигурацию сервера под любые типы задач: от создания корпоративного чат-бота до масштабного локального инференса LLM в дата-центре.
LoRA и QLoRA в экосистеме ИИ-инструментов
Интеграция LoRA и QLoRA в современные ИИ-системы стала не просто приятной оптимизацией, а неотъемлемой частью любого интеллектуального приложения. Библиотека PEFT от Hugging Face предлагает широчайший спектр инструментов для работы с методами LoRA и QLoRA: их можно легко использовать с популярными окружениями для запуска моделей, такими как LM Studio, Ollama или высокопроизводительным vLLM для продакшена, а весь запуск дообученной модели сводится к загрузке весов и подключению нескольких небольших файлов адаптеров. Эта простота интеграции — главный драйвер массового распространения PEFT-технологий. Стоит отметить, что дообучение — не единственный способ кастомизации моделей, и в отдельной статье мы подробно сравним его с другим популярным подходом под названием RAG (Retrieval-Augmented Generation).

Сравнение методов оптимизации Full-Finetuning, LoRA и QLoRA. Источник: .
Выводы
LoRA и QLoRA не могли не стать прорывом в области дообучения LLM, поскольку эти методы смогли по-настоящему демократизировать кастомизацию нейросетей, сделав ее доступной не только для IT-гигантов, но и для небольших компаний или даже обычных юезров. Но важно понимать, что хотя базовые эксперименты с LoRA и QLoRA действительно можно проводить на одной потребительской видеокарте, для реальных бизнес-задач, где важна скорость и стабильность, необходимы профессиональные серверные решения с несколькими GPU. Так или иначе, LoRA и QLoRA предоставили всему миру ключ к мощному ИИ, а правильное железо позволяет использовать этот ключ для открытия любых дверей в мир эффективных интеллектуальных приложений.
