vLLM добавили плагины для удобной модификации движка
Введение
vLLM является одним из самых популярных открытых движков инференса искусственного интеллекта, однако несмотря на его внушительный функционал, многим командам все равно необходимо переписывать части кода, чтобы добавить желаемые возможности: адаптировать планировщик, обновить механизм KV-кэша, добавить оптимизации или вмешаться в процесс выполнения модели. В этот момент возникает вопрос. Чтобы подобные модификации можно было выполнять, быстро, чисто, удобно и без необходимости внесения изменений в репозиторий или создания собственных форков, разработчики vLLM добавили систему плагинов.
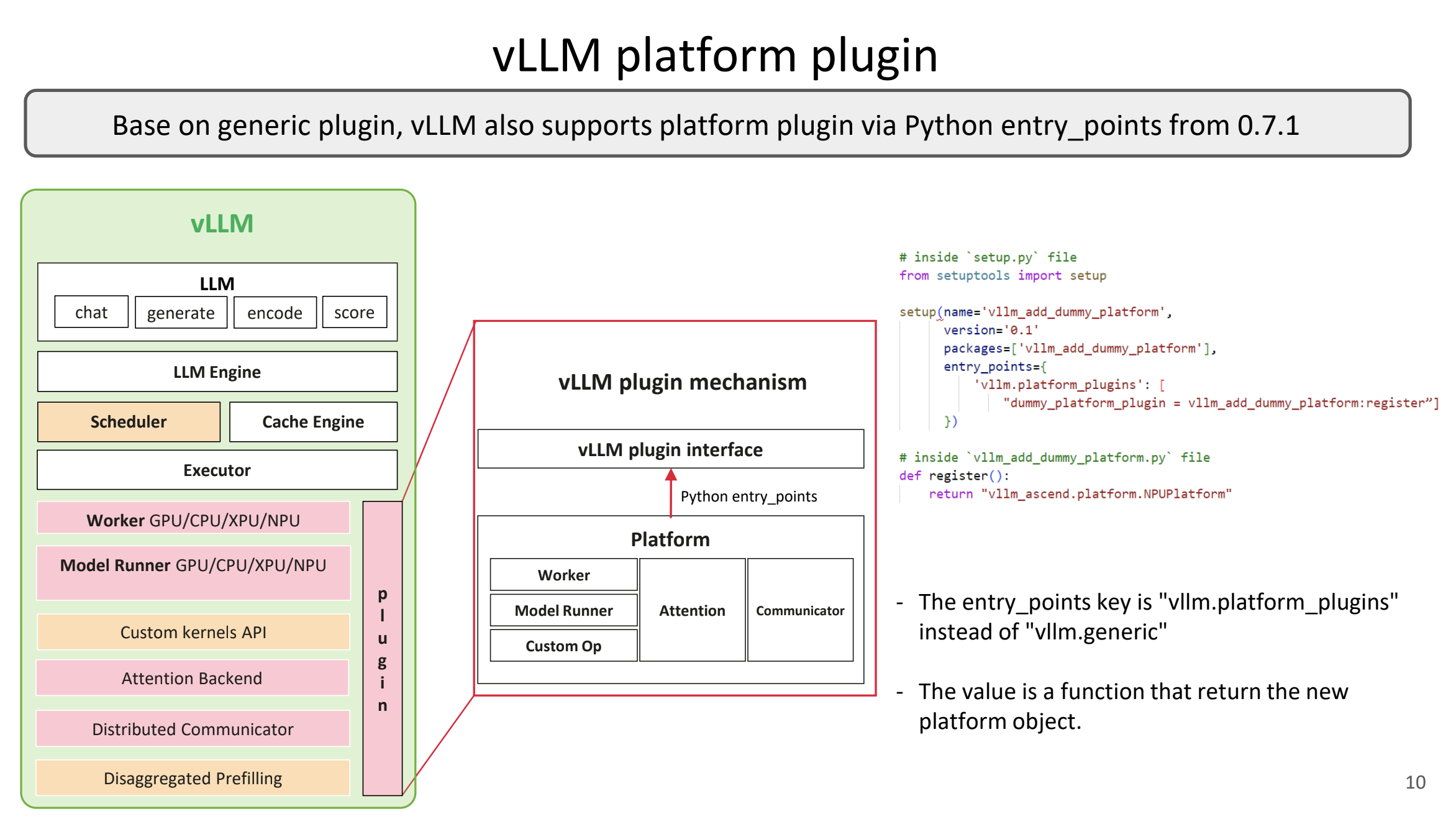
Подробнее о системе плагинов vLLM
Система патчей vLLM позволяет вносить точечные, структурированные и контролируемые изменения в движок без модификации исходного кода. Плагины загружаются автоматически во всех процессах, запускаются до инициализации модели, чтобы исключить конфликты и проблемы синхронизации, и обеспечивают предсказуемое поведение нейросетей при инференсе. Плагин может содержать только измененный фрагмент, активироваться по необходимости и иметь ограничение по минимальной версии vLLM. Один контейнер может использоваться сразу для нескольких моделей — каждая модель может выбирать свой набор патчей через переменные окружения. Все это обеспечивает изолированность, модульность и простоту сопровождения изменений в долгосрочной перспективе. Важным элементом такой архитектуры является жизненный цикл подключения плагинов. vLLM вызывает загрузку общих плагинов автоматически в каждом созданном процессе, будь то основной процесс, CPU-воркер или GPU-воркер. Для разработчиков такой подход означает, что любые модификации становятся точными, компактными и безопасными для обновлений. Нет необходимости копировать файлы, поддерживать форки, повторно применять патчи или сталкиваться с ошибками, вызванными некорректным переопределением модулей. Все работает через штатный механизм расширения, официально поддерживаемый vLLM, что повышает надежность и минимизирует ошибки.
Выводы
Система патчей vLLM — это одно из самых полезных обновлений движка за последнее время. Благодаря нему ИИ-разработчики смогут удобно и эффективно настраивать систему под свои нужды, не прибегая к масштабным модификациям кода vLLM, при этом система сама обеспечит изоляцию работы плагинов и стабильность при инференсе ИИ. Такой подход особенно полезен на фоне регулярных обновлений vLLM и растущих требований к гибкости инфраструктуры.
