Instruction Tuning и SFT: как дообучить модели под конкретные задачи в 2025 году
Введение
Одна из самых распространенных проблем использования больших языковых моделей – они не всегда понимают, как именно нужно выполнять пользовательские инструкции. Модель, способная написать сложный технический отчет, может давать излишне упрощенные или стилистически неподходящие ответы на запросы ваших сотрудников. Причина такого поведения ИИ заключается в фундаментальном несоответствии между целью предобучения (предсказание следующего слова) и целью пользователя (получение точного и адекватного ответа на инструкцию). Но как добиться того, чтобы модель отвечала только по делу и вам не приходилось каждый раз максимально подробно писать промпт? Для этого существуют методы Instruction Tuning и Supervised Fine-Tuning (SFT), которые учат модель вникать в ваши инструкции и отвечать в нужной манере. В этой статье мы расскажем вам, что из себя представляют эти техники дообучения LLM, как их правильно применять, в каких сценариях их использовать и какая система понадобится для работы с Instruction Tuning и SFT.
Что такое Instruction Tuning и SFT
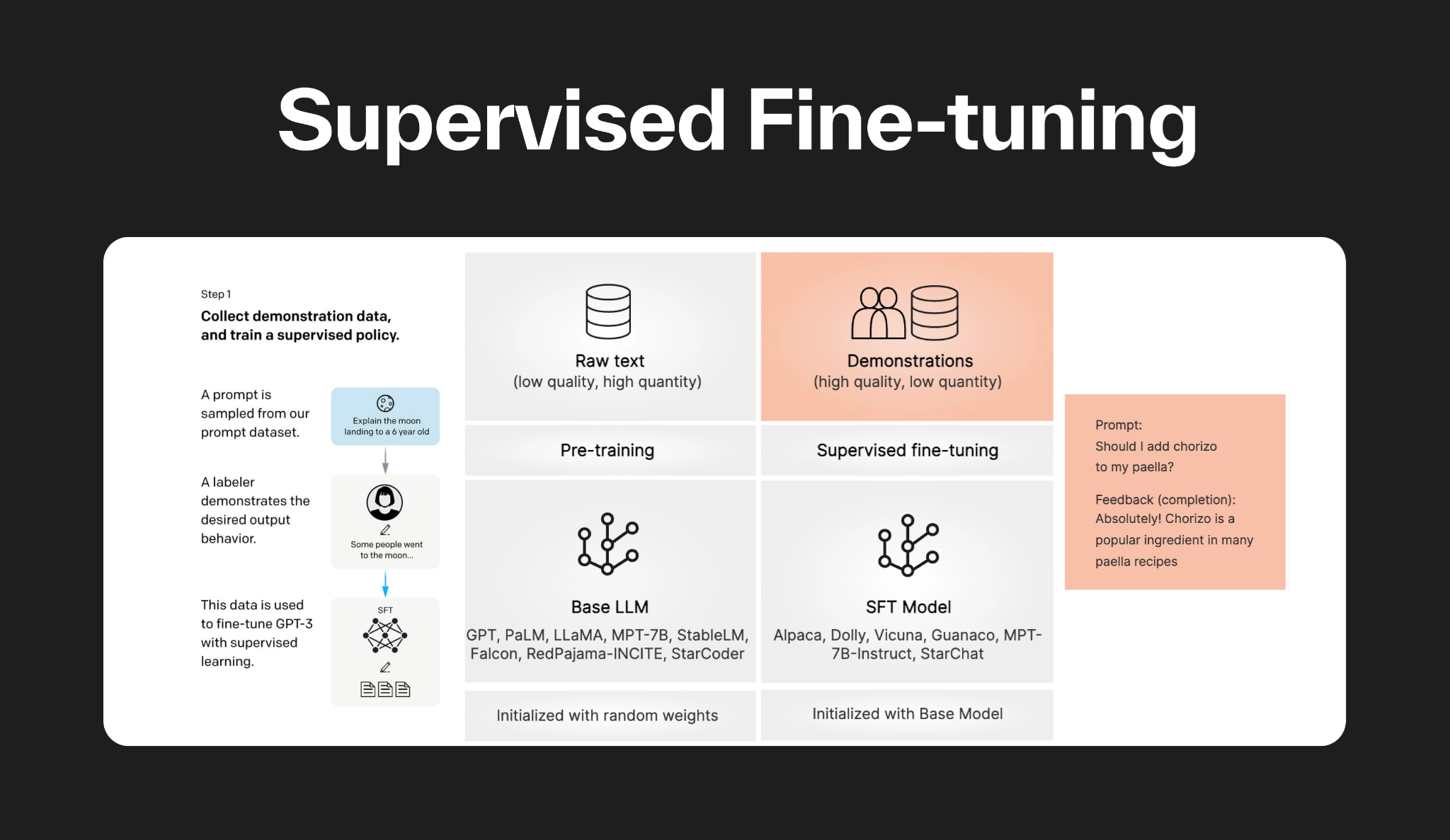
SFT (Supervised Fine-Tuning) – это классический метод контролируемого дообучения LLM, при котором предварительно обученная модель продолжает обучение на данных, размеченных как пары “инструкция-ответ”. Веса модели обновляются особым образом с использованием метода обратного распространения ошибки, при котором модель учится предсказывать каждый токен правильного ответа, основываясь на заданной инструкции и, возможно, дополнительном контексте. По сути, SFT выступает в роли моста между предсказанием следующего слова и следованием инструкциям пользователя.
Instruction Tuning является более продвинутой версией SFT, в которой фокус смещен именно на то, чтобы научить модель понимать и четко следовать инструкциям пользователя. Ключевое отличие от классического тонкой настройки LLM, целью которой часто является введение в модель новых данных, заключается в акценте не на то, что должна отвечать модель, а на то как она должна отвечать – формат, стиль и другие правила, соблюдение которых для базовых LLM обычно дается с трудом. Такой подход позволяет создавать чат-ботов и ИИ-ассистентов, которые не просто обладают знаниями, но понимают политику компании, придерживаясь установленной тональности и структуры коммуникации.

Схема работы метода дообучения LLM Supervised Fine-Tuning. Источник: .
Методы и практики Instruction Tuning
Если использовать Instruction Tuning с первым попавшимся набором данных, то вы не только не получите нужного эффекта от дообучения, но и с высокой долей вероятности кастрируете даже базовые функции LLM из-за ошибки “катастрофического забывания”. Именно поэтому от качественного выбора данных зависит 90% успеха дообучения вашей LLM. Конечно, можно использовать ресурсы с открытыми датасетами (например, Alpaca, Dolly) или синтетические наборы данных, которые может сгенерировать сама нейросеть, но самой ценной информацией для дообучения являются корпоративные наборы пар “запрос-ответ”, составленные вашими самыми опытными сотрудниками.
Также к Instruction Tuning можно подключить дополнительные методы дообучения, вроде LoRA и QLoRA, благодаря чему можно эффективнее оптимизировать огромные языковые модели даже на скромном оборудовании. Они замораживают веса исходной модели и добавляют небольшие веса-адаптеры, что значительно экономит вычислительные ресурсы и память, сокращая количество обучаемых параметров в тысячи раз.
Alignment Tuning – это еще один современный ИИ-тренд, включающий такие методы, как DPO (Direct Preference Optimization) и ORPO (Odds Ratio Preference Optimization). Они используются для тонкой корректировки поведения модели на основе человеческих предпочтений, чтобы ответы были не только правильными, но и полезными, безопасными и этичными. По сути, это тот же самый Instruction Tuning, но с дополнительными инъекциями, которые не позволят клиентам обдурить вашего дообученного чат-бота.
Все эти передовые инструменты предоставляют ИИ-инженерам максимальную гибкость в кастомизации LLM, при этом сохраняя баланс между качеством ответов, стоимостью развертывания и скоростью дообучения под конкретные нужды компании.

Сравнение метода Instruction Tuning с Pretrain-Fine-Tuning и традиционным Prompting. Источник: .
Подготовка данных для SFT
Аналогично методу Instruction Tuning, в SFT правильный выбор данных тоже имеет решающее значение. Но так как Supervised Fine-Tuning не так сильно ориентирован на следование инструкциям, как Instruction Tuning, критерии выбора датасета для него еще более строгие – необходимо безупречное качество разметки, контроль данных для предотвращения утечки и поддержание баланса между различными типами задач.
Такие платформы, как Hugging Face Datasets, предоставляют доступ к множеству уже размеченных данных, но их обязательно нужно валидировать, актуализировать и дополнять корпоративной информацией вашей компании. Кроме того, исследования показывают, что даже в известных наборах данных, таких как databricks-dolly-15k, могут встречаться фактические ошибки, неточные выводы, неполные инструкции и орфографические ошибки. Автоматизированные решения, такие как Cleanlab Studio, помогают выявлять подобные проблемы, оценивая достоверность ответов и находя токсичный или конфиденциальный контент, но даже такие методы не исключают необходимость в ручной выборке данных для дообучения LLM. Этот процесс включает разделение данных на три выборки:
- Обучающую: для фундаментального обучения модели;
- Валидационную: для промежуточной оценки качества ответов модели;
- Тестовую: для итоговой оценки ответов модели на этапе вывода.
На этапе тестовой выборки также подключаются дополнительные метрики для оценки релевантности ответов LLM в определенных типах задач, скорости генерации ответов и точному следованию пользовательских инструкций.

Как работает метод Supervised Fine-Tuning и его модифицированная версия Reinforced-Fine-Tuning. Источник: .
Инфраструктура для Instruction Tuning
Метод Instruction Tuning и SFT требует больших вычислительных ресурсов, поскольку уже на этапе предобработки данных активно задействуются мощные CPU для эффективной токенизации и управления большими наборами информации, а уже на самом этапе дообучения понадобятся высокопроизводительные GPU-ускорители и быстрая система хранения данных, в идеале, на базе NVMe накопителей для оперативной подгрузки информации. Особенно большая нагрузка возникает при длительных сессиях дообучения моделей с внушительным количеством параметров, при этом на первый план выходит не только количество системных ресурсов, но и отказоустойчивость вашей инфраструктуры. Многие думают, что работа с весами LLM — это очень тяжелая операция, которая займет огромное количество времени даже на самых мощных видеокартах. Однако это не совсем так, ведь если вы дообучаете LLM на GPU с высокоскоростной памятью HBM, которая гораздо более эффективно обрабатывает градиенты весовых коэффициентов, оптимизировать LLM можно всего за несколько часов. Именно такие решения, оснащенные передовой видеопамятью HBM, можно найти в ассортименте компании SevreFlow. У нас вы можете приобрести мощные H200 и H100 NVL на базе HBM3E и HBM3, более бюджетные A100 на базе HBM2E, а также массу других готовых графических и сопутствующих решений для работы с большими языковыми моделями. А если вы не знаете, какое именно оборудование необходимо для удовлетворения ваших потребностей, наши опытные консультанты подберут наиболее оптимальное решение под ваш бюджет и задачи.
Примеры применения SFT и Instruction Tuning
Рассмотрим три основных сценария использования методов SFT и Instruction Tuning:
- Корпоративные чат-боты и ассистенты: один из самых распространенных примеров – создание ИИ-ассистентов, которые не только обладают знаниями из базы данных компании, но и общаются в установленном корпоративном стиле, будь то формальный язык для юридической фирмы или более дружелюбный и поддерживающий для службы поддержки клиентов.
- Специализированные генераторы документации: модели можно дообучить для автоматического создания технической документации, ведения отчетов или генерации маркетинговых материалов, которые будут строго соответствовать внутренним стандартам компании по структуре, терминологии и тональности.
- Адаптация мультимодальных моделей: методы Instruction Tuning выходят за рамки текста, позволяя дообучать модель (например, Whisper) распознавать речь с узкоспециальной лексикой (медицинские заключения, инженерные термины), чтобы значительно повысить точность транскрибации в этой области.

Схема работы метода Instruction Tuning, оптимизированного для работы с мультимодальными LLM. Источник: .
Выводы
Многие думают, что локального инференса достаточно, чтобы ИИ-модель стала “вашей”, но по-настоящему “вашей” ее делают передовые методы дообучения, такие как Instruction Tuning и SFT. Именно эти технологии меняют фундаментальные принципы работы нейросетей, делая их не столько интеллектуальными, сколько полезными и, что самое главное, максимально отзывчивыми. Но помните, что просто внедрить Instruction Tuning и SFT, дообучив LLM на сомнительном наборе данных, будет фатальной ошибкой – используйте только качественные наборы данных из открытых источников или собственные датасеты с информацией вида “запрос-ответ”, предварительно обработав их в специализированных сервисах, устранив возможные ошибки. Только это сможет сделать дообучение ИИ максимально эффективным.
