DeepSeek представила DeepSeek-OCR 2: новый уровень визуального восприятия в ИИ
Введение
DeepSeek представила второе поколение своей OCR-модели — DeepSeek-OCR 2, сделав акцент не просто на распознавании текста, а на полноценном понимании структуры документов. Новая версия имеет 3 миллиарда параметров и модифицирована обновленным визуальным энкодером DeepEncoder V2, который радикально меняет сам подход к считыванию изображений. Если классические VLM и OCR-системы по-прежнему воспринимают изображение как статичную сетку пикселей, то DeepSeek делает ставку на последовательное чтение документа, как это делает человек, что напрямую влияет на точность и устойчивость в сложных сценариях.
Подробнее о DeepSeek-OCR 2
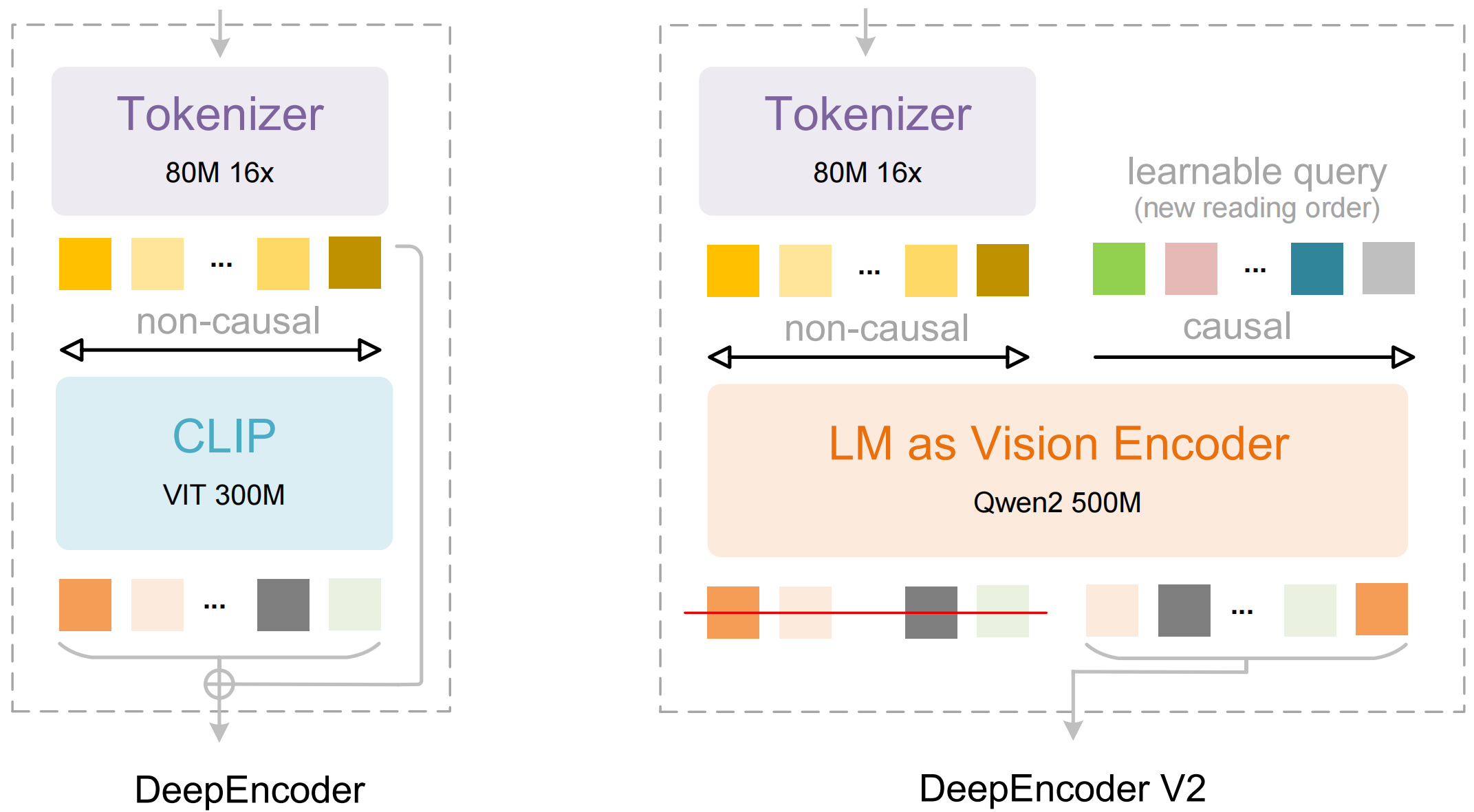
Ключевым техническим нововведением DeepSeek-OCR 2 является визуальный энкодер DeepEncoder V2. В традиционных моделях изображение читается линейно, от верхнего левого угла к нижнему правому, что хорошо работает для простых документов, но дает сбои в многостолбцовых макетах, таблицах и смешанном тексте. DeepEncoder V2 сначала формирует глобальное представление страницы, а затем обучается определять логический порядок восприятия элементов — аналогично тому, как человек сначала "схватывает" структуру страницы, а уже потом читает ее содержимое. Модель лучше понимает, что является заголовком, что — телом текста, а что — вспомогательной информацией, и реже теряет контекст при переходе между блоками. Именно за счет этого DeepSeek-OCR 2 демонстрирует заметный прирост качества не только в классическом OCR, но и в задачах понимания документов.
При этом, модель остается крайне компактной — всего 3B параметров, что делает ее пригодной для локального развертывания и тонкой настройки. При этом, по внутренним тестам DeepSeek, новая версия на 4% превосходит предыдущий DeepSeek-OCR и обходит Gemini 3 Pro в ряде бенчмарков, ориентированных на анализ сложных документов. Это особенно важно, поскольку разрыв между чистым OCR и задачами на понимание документов становится все более критичным для корпоративных сценариев, таких как анализ контрактов, финансовых отчетов и форм. Код DeepSeek-OCR 2 уже доступен для скачивания на Hugging Face и GitHub.
Выводы
DeepSeek-OCR 2 — это шаг от классического оптического распознавания символов к более осмысленному чтению документов. За счет DeepEncoder V2 модель начинает воспринимать страницу как логическую структуру, а не как набор пикселей, что напрямую отражается на качестве в реальных, сложных макетах. Сочетание компактного размера и улучшенной точности делает DeepSeek-OCR 2 сильным конкурентом коммерческим VLM-решениям и показывает, что будущее OCR лежит не в увеличении разрешения, а в понимании того, как документы читают реальные люди.
