DeepSeek-OCR — неожиданный релиз мощной модели для распознавания текста
Введение
Компания DeepSeek анонсировала новую модель оптического распознавания символов — DeepSeek-OCR (Contexts Optical Compression), предназначенную для извлечения текста из документов с последующим сжатием данных.
Подробнее о DeepSeek-OCR
Модель построена на архитектуре Mixture of Experts (MoE). Объем модели составляет 6,68 ГБ, что соответствует примерно 3,6 миллиардам параметров, при этом она поддерживает вычислительную точность BF16, что обеспечивает баланс между производительностью и эффективностью.
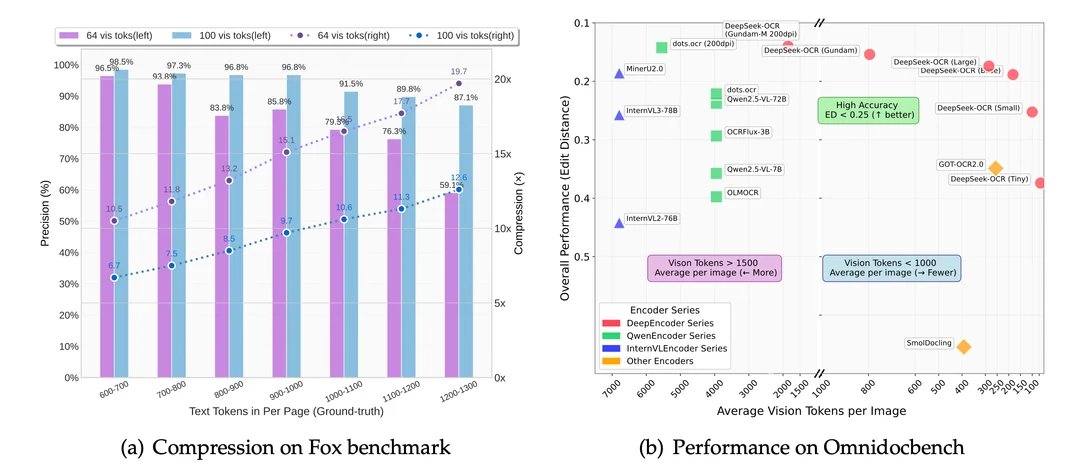
DeepSeek-OCR поддерживает четыре основных режима работы, различающихся по разрешению и числу визуальных токенов:
- Tiny: 512×512 (64 токена);
- Small: 640×640 (100 токенов);
- Base: 1024×1024 (256 токенов);
- Large: 1280×1280 (400 токенов).
Кроме того, предусмотрен специальный режим Gundam с динамическим расширением n×640×640 + 1×1024×1024, который позволяет гибко масштабировать качество анализа в зависимости от сложности документа.
По данным компании, новая OCR-модель способна обрабатывать до 33 миллионов страниц в день при использовании кластера из 20 узлов по 8 GPU NVIDIA A100 (40 ГБ). Для открытой и компактной OCR-системы такие показатели считаются крайне высокими, что делает DeepSeek-OCR одним из самых производительных решений в своем классе открытых LLM. Веса модели уже лежат на GitHub и Hugging Face.
Выводы
Вполне возможно, что компания DeepSeek готовит к релизу новое поколение VL-нейросетей на фоне резкого взлета популярность больших языковых моделей для распознавания текста от Alibaba, IMB и других компаний. Также не исключено, что DeepSeek-OCR станет частью не просто семейства, а флагманской мультимодальной нейросети, вроде DeepSeek R2 или DeepSeek V4.
