Запуск Qwen3 на Huawei Atlas 300I Duo: бюджетный инференс топовой LLM

Введение
Продавать ИИ-железо нынче недостаточно — нужно еще и объяснять, как оно работает и как запускать на нем нейросети. С решениями Nvidia и AMD все просто: вставил, скачал нейросеть, запустил в интерфейсе на свой вкус, и именно за эту нативность и простоту эксплуатации таких GPU ценники на них бывают просто заоблачные. То ли дело решения компании Huawei, например, ИИ-ускоритель Atlas 300I Duo 96 ГБ. Plug-and-play эту карточку точно не назвать, но взамен она предлагает огромный объем памяти и достойную производительность по адекватному прайсу, хоть и с настройкой придется немного покопаться. А чтобы вам не пришлось самим ломать голову с локальным запуском LLM на этом китайском NPU, специалисты компании ServerFlow объяснят вам весь процесс инференса Qwen3-8B на ИИ-ускорителе Huawei Atlas 300I Duo.
Характеристики Huawei Atlas 300I Duo
Huawei Atlas 300I Duo — это однослотовый ИИ-ускоритель от компании Huawei. Решение оснащается двумя NPU-чипами Ascend 310P, которые в сумме дают ИИ-производительность до 280 TOPS в INT8 и 140 TFLOPS в FP16, при этом энергоэффективность достигает 1,86 TOPS/Вт. Ускоритель имеет далеко не самую быструю память LPDDR4X, но благодаря внушительному объему в 96 ГБ, на нем можно с легкостью локально инференсить большие языковые модели через программный стек Huawei CANN. Помимо ИИ-производительности, карточка также поддерживает гибридные вычисления для задач компьютерного зрения, NLP и видеоаналитики, но об этом как-нибудь в другой раз. С подробными характеристиками Huawei Atlas 300I Duo можно ознакомиться тут.

Передовой китайский ИИ-ускоритель Huawei Atlas 300I Duo с 96 ГБ LPDDR4X.
Подготовка драйверов и CANN
На первом этапе вам потребуется установить драйверы правильных версий. Возможно, вы уже смотрели наш предыдущий гайд по подготовке окружения и зависимостей для работы с Huawei Atlas 300I Duo, где мы подробно изложили процесс установки драйверов. С тех пор процесс подготовки драйверов почти не изменился, но зато успели поменяться их версии — драйверы 25.0.RC1.1 и CANN 8.2.RC1.Alpha уже неактуальны, поэтому вместо них нужно установить версии 25.2.0 и CANN 8.2.RC1.

Вывод команды npu-smi-info: видно два чипа Ascend 310P3 под управлением драйвера 25.20.
Скачать драйвера и CANN можно на официальном сайте , а также мы выложим их на наш .

Драйверы, cann kernel и cann toolkit на FTP-сервере SeverFlow.
Помните, что для скачивания необходимо пройти авторизацию на сайте — верификацию можно пройти через российский номер телефона. Также обязательно выберите тип вашей системы (x86/Arm), тип файла (run в нашем случае), а для CANN необходимо выбрать корректную версию программного стека, в случае с Huawei Atlas 300I Duo понадобится Ascend-cann-kernels-310p_8.2.RC1_linux_x86_64.
После установки проверить текущую версию ПО можно командой:
cat /usr/local/Ascend/ascend-toolkit/latest/version.cfg.jpg "Версии драйверов и CANN для Huawei Atlas 300I Duo")
Видно все компоненты Huawei CANN с единой версией 8.2RC.1.
Стоит отметить, что запустить инференс на Huawei Atlas 300I Duo можно даже из-под Proxmox благодаря технологии gpu passthrough, так что ничто не помешает вам тестировать это передовое решение на виртуальных машинах.
Скачивание модели Qwen
На втором этапе вам потребуется скачать саму ИИ-модель для инференса. Мы будем запускать модель Qwen3-8B — современную компактную ИИ-модель от Alibaba с функцией размышления, однако вы можете выбрать любую другую нейросеть на ваш вкус (главное, чтобы хватило VRAM). Поскольку Huawei Atlas 300I Duo поддерживает только форматы вычислений FP16 и INT8, а новомодные квантования Q4_K_M и даже, казалось бы, совместимый с INT8 режим W8A8, недоступны для работы с этим ИИ-ускорителем. Все из-за инструментария Huawei, который компилирует код нейросетей для локального запуска, и при использовании неподходящего квантования компиляция может произойти некорректно. Лучше не ломать себе голову и просто запускать инференс в нативных режимах работы ускорителя — памяти у вас и так хватит с головой. После выбора подходящей модели, скачайте ее веса на устройство через huggingface_hub, Git LFS или другую библиотеку LLM.

Страница ИИ-модели Qwen3-8B от Alibaba на Huggin Face. Источник: .
Подготовка Docker и контейнера с MindIE
Поскольку мы будем развертывать Qwen3-8B через контейнеры (что и вам советуем), также скачаем Docker через , следуя предоставленным на нем инструкциям. Когда Docker подготовлен, можно переходить к запуску самого контейнера с движком инференса Huawei MindIE — аналог vLLM, SGLang и llama.cpp, но с китайским колоритом и оптимизациями для работы ИИ-ускорителями Huawei. Не стоит его чураться: он корректно работает из коробки, демонстрирует стабильную скорость генерации токенов и в целом движок работает весьма быстро, а самое главное, что для него не нужен отдельный формат весов. Затем возьмите образ контейнера (13 ГБ) с :
2.1.RC2-300I-Duo-py311-openeuler24.03-lts
Страница с выбором контейнеров Huawei MindIE. Нас интересует контейнер 2.1.RC2-300I-Duo-py311-openeuler24.03-lts. Источник: .
В контейнер зашита операционная система OpenEuler, Python 3.11 и непосредственно движок MindIE.
Чтобы скачать контейнер, воспользуйтесь командой:
docker pull swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:2.1.RC2-300I-Duo-py311-openeuler24.03-ltsЗатем запустите Docker-образ с помощью этой команды:
docker run -itd --net=host --ipc=host --shm-size=2g --name qwen-mindie-hf --device=/dev/davinci0 --device=/dev/davinci1 --device=/dev/davinci_manager --device=/dev/hisi_hdc --device=/dev/devmm_svm -v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro -v /usr/local/sbin:/usr/local/sbin:ro -v /data/models:/data/models -v /home/serverflow/.cache/huggingface:/root/.cache/huggingface:ro swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:2.1.RC2-300I-Duo-py311-openeuler24.03-lts bashКоманда дает NPU-чипам и davinci-менеджеру доступ к контейнеру, прокидывает папку с драйверами, ИИ-моделью, системными утилитами и кэш Hugging Face.
Для входа в контейнер выполните следующую команду:
docker exec -it qwen-mindie-hf bash
Вход в Docker-контейнер с движком инференса и ИИ-моделью.
Рекомендуем также прописать команду для проверки работы чипов внутри контейнера:
npu-smi infoЕсли внутри контейнера отображается NPU-ускоритель, готовая среда и mindie, то все сделано корректно, а значит, можно переходить к конфигурированию.
Настройка конфигурации для Ascend
В первую очередь, вам потребуется отредактировать конфиг-файл mindie:
nano /usr/local/Ascend/mindie/latest/mindie-service/conf/config.jsonПодробные настройки конфига мы выложим в нашем Telegram-канале. Найти их можно по хэштегу #atlas300iduo.

Python-скрипты для тестов и настройки конфигурации JSON уже доступны в Telegram-канале ServerFlow!
Обратите внимание, что у mindie по умолчанию работает на 1025 порте, к которому в дальнейшем нужно будет подключиться через веб-интерфейс, а также важно отключить HTTPS, чтобы минимизировать дополнительную настройку.

Настройки конфигурационного файла ИИ-движка mindie.
Затем нужно отредактировать конфиг-файл самой модели Qwen3-8B, которую вы уже скачали ранее и прокинули к ней директорию. Перейти в конфиг можно с помощью команды:
nano /root/.cache/huggingface/hub/models--Qwen--Qwen3-8B/snapshots/b968826d9c46dd6066d109eabc6255188de91218/config.jsonВ нем необходимо поменять только одну настройку, которая касается работы ИИ-ускорителя Huawei Atlas 300I Duo — параметр torch-dtype нужно поменять с bfloat16 на float16, так как ускоритель не поддерживает режим BF16.

Настройки конфигурационного файла ИИ-модели Qwen3-8B.
Запуск модели Qwen3-8B
Все подготовительные процедуры сделаны, поэтому теперь можно заняться запуском ИИ-модели. Для этого перейдите в директорию с помощью команды:
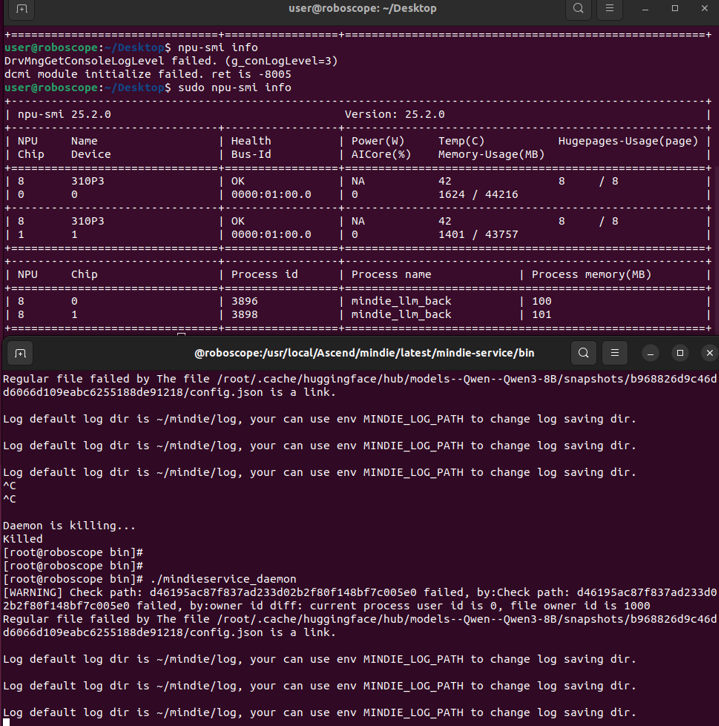
cd /usr/local/Ascend/mindie/latest/mindie-service/binОзнакомьтесь с файлами, которые доступны в директории. В ней нас интересует mindieservice-daemon, который является сервером инференса. Запустите его командой:
./mindieservice_daemonПосле 40 секунд ожидания вы увидите надпись Daemon start success, а значит, сервер успешно запущен и он работает с моделью Qwen3-8B, размещенной по указанному ранее в конфиге адресу — на порте 1025 HTTP.

Запуск сервера инференса mindieservice-daemon.
Теперь необходимо подключить сервер к веб-интерфейсу через API для работы с локальными ИИ-моделями OpenWebUI. Чтобы проверить работоспособность сервера, можно воспользоваться утилитой curl. Для этого введите следующую команду:
curl http://127.0.0.1:1025/v1/modelsЕсли в ответ вы получили осознанный вывод о запуске сервера с Qwen3-8B, значит все работает корректно.
После этого этого перейдите в OpenWebUI, зайдите в настройки администратора, и в настройках подключения OpenAI API укажите эндпоинт http://192.168.90.117:1025/v1, где 192.168.90.117 — это локальный адрес (у вас будет свой), а 1025 — порт подключения. Напоминаем, что подключаться нужно через HTTP, а не через HTTPS.

Настройки OpenAI API в OpenWebUI
Если все введено корректно, в разделе моделей OpenWebUI должна появится Qwen3-8B.

Выберите ее и смело задавайте свой первый вопрос локальной нейросети!
Теперь ИИ-модель Qwen3-8B будет доступна в OpenWebUI.
Выберите ее и смело задавайте свой первый вопрос локальной нейросети!

Инференс Qwen3-8B на ИИ-ускорителе Huawei Atlas 300I Duo.
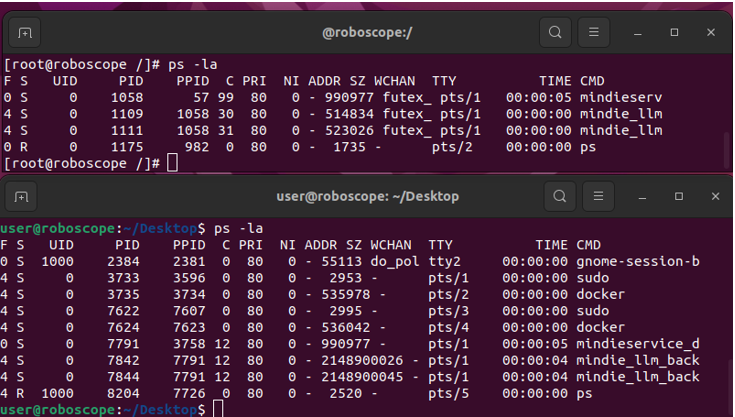
Можете вновь зайти в CLI и ввести команду npu-smi info, чтобы увидеть, как модель загружает ИИ-ускоритель. Не удивляйтесь, что столь маленькая модель так сильно съедает VRAM. Дело в том, что Qwen3-8B, несмотря на компактные размеры, довольно тяжелая и требует минимально 16 ГБ VRAM, но основной рост потребления памяти связан с KV-cache, который MindIE по-умолчанию выделяет весьма и весьма агрессивно. Тот же принцип действует и в vLLM, который резервирует большую часть VRAM под оптимизированный KV-cache и внутренние буферы, чтобы обеспечить лучшую скорость генерации токенов. Именно поэтому инференс съедает почти всю доступную VRAM.
Также вы увидите, что каждый чип ускорителя Huawei Atlas 300I Duo греется примерно на 80 Вт, на оба чипа накинут процесс mindie_llm_back — это означает, что оба NPU выполняют инференс Qwen3-8B.

Нагрузка на NPU-чипы Huawei Atlas 300I Duo во время инференса Qwen3-8B.
Тестирование инференса и замер TPS
Чтобы измерить скорость генерации токенов, мы подготовили пару элементарных тестов. Первый тест будет заставляет модель инференсить большой текст, вырабатывая токены, после чего он подсчитывает количество токенов в секунду.
Файлы с Python-скриптами для тестов мы также залили в наш Telegram-канал. Найти их можно по хэштегу #atlas300iduo.
После того, как Pyhon-файл закинут на сервер, введите команду:
python3 tps_test.pyДождитесь выполнения теста и скрипт автоматически покажет результаты: количество токенов в секунду достигло внушительных 17,67 TPS — примерно того же уровня TPS достигает инференс Grok и ChatGPT.
Напомним, что это результат FP16-модели без дополнительных оптимизаций. Добавив ИИ-тюнинг, например, механизм FlashAttention, результат можно улучшить, но в рамках нашего гайда мы не стали усложнять процесс инференса.

Тестирование TPS при инференсе Qwen3-8B на Huawei Atlas 300I Duo.
Запустим еще один тест, который генерирует аж 50 параллельных запросов. Загрузите Pyhon-файл со скриптом и запустите его командой:
python3 tps_test_parallel.pyРезультаты: в среднем 11,59 токенов в секунду на запрос, и это при инференсе 50 параллельных запросов! Только вдумайтесь: при обращении 1 пользователя, ускоритель обеспечивает около 18 токенов в секунду, но при обращении 50 пользователей они получают 11 токенов в секунду, что суммарно обеспечивает колоссальный показатель TPS в 572 токенов, а это уже уровень самых топовых ИИ-ускорителей. Возможно, однопоточный режим Huawei Atlas 300I Duo работает некорректно или свою роль играет наличие 2 NPU, либо ускоритель специально создавался с акцентом именно на многопоточные задачи, но факт остается фактом — ИИ-производительность китайского NPU-решения впечатляет. Причем, это результат без дополнительного тюнинга. Если сменить фреймворк, например, на более производительный MindSpore, можно добиться еще большей эффективности.

Тестирование TPS в инференсе Qwen3-8B на Huawei Atlas 300I Duo при 50 одновременных запросах.
Выводы
Huawei Atlas 300I Duo — это вполне рабочий ИИ-ускоритель, который позволяет локально запускать современные ИИ-модели с действительно высокой производительностью, хоть и с определенными, не критичными условностями. Конвертация в нужный формат вычислений и выбор подходящих весов накладывают определенные трудности, но нужно понимать, что NPU от Huawei — это не универсальный мультитул для любых типов вычислений, а узкоспециализированное решение для работы с ИИ в FP16 и INT8, а также для обработки видеопотоков. Взамен Huawei Atlas 300I Duo предлагает отличную ИИ-производительность по достойной цене, что выгодно выделяет его на фоне GPU-решений Nvidia и AMD за оверпрайс.