Tencent представила HunyuanOCR: новая веха в мультимодальном распознавании текста
Введение
Китайская корпорация Tencent представила новую ИИ-модель HunyuanOCR, которая представляет из себя новое поколение мультимодальных систем распознавания текста. Разработчики позиционируют модель как инструмент, способный изменить представление о том, каким должно быть OCR-решение в эпоху больших LLM. Несмотря на объем всего в 1 миллиард параметров, система уже демонстрирует производительность на уровне ведущих отраслевых моделей, при этом оставаясь компактной и простой в использовании.
Подробнее о HunyuanOCR
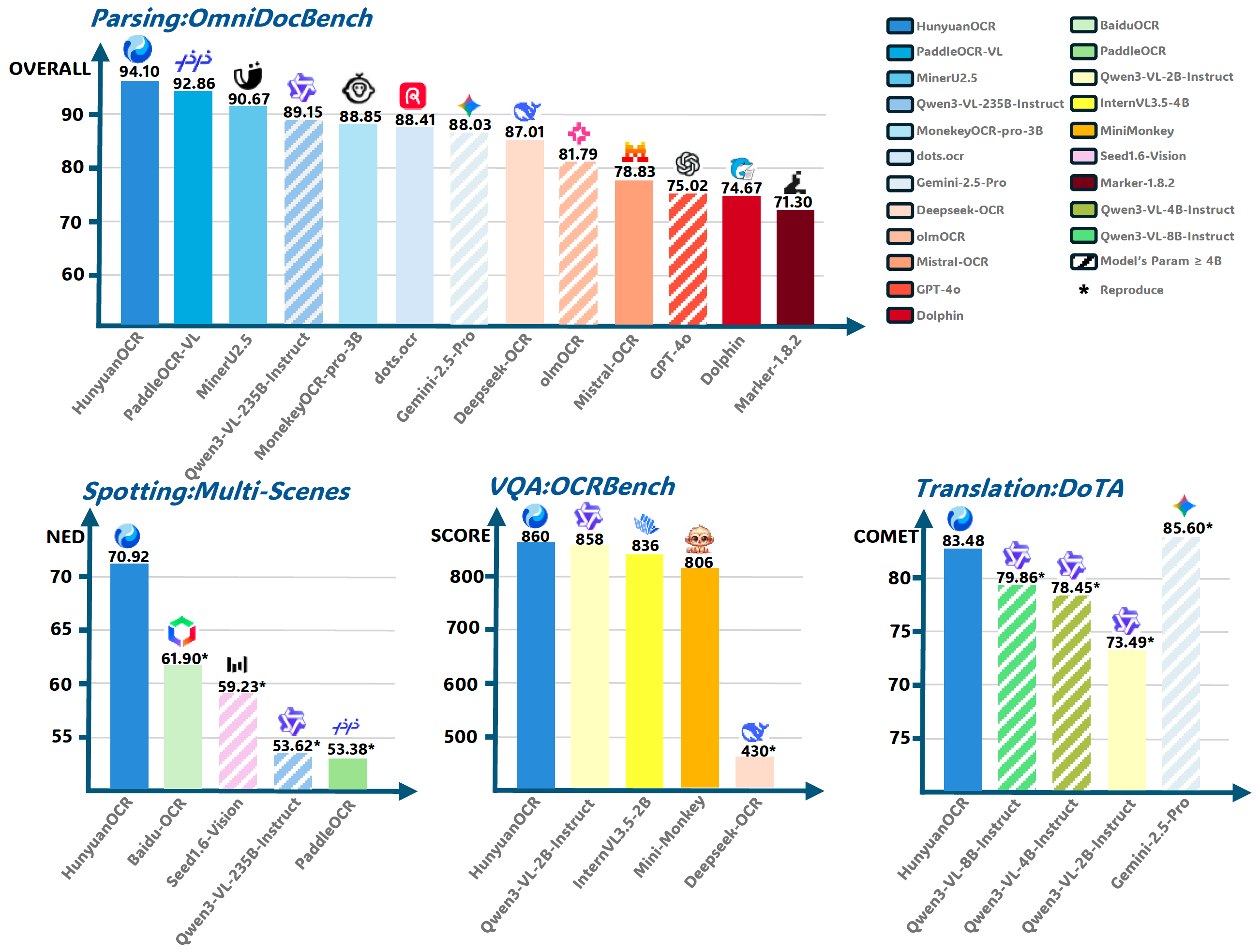
HunyuanOCR сочетает мультимодальную архитектуру с оптимизированной стратегией обучения, что позволяет модели работать на уровне крупных OCR-систем при значительно меньших вычислительных затратах — модель уже превосходит популярные нейросети PaddleOCR-VL, Qwen3-VL-235b, Gemini-2.5 Pro и DeepSeek-OCR. Модель уверенно справляется с задачами обнаружения текста, его распознавания, сложного структурного анализа документов и открытого извлечения информации. Она также способна работать с субтитрами видео, выполнять перевод текстов с изображений и проводить проверку качества документа. В отличие от каскадных систем, где для распознавания документов требуется множество отдельных ИИ-модулей, HunyuanOCR придерживается сквозного подхода: пользователь формулирует одну инструкцию и получает готовый результат, что значительно ускоряет рабочие процессы.
Важным достижением является полноценная многоязычная поддержка. Модель способна распознавать и анализировать текст более чем на сотне языков, включая сценарии, где требуется переключение между несколькими языковыми системами в пределах одного документа. Это делает ее актуальной для международного документооборота, глобальных сервисов и приложений, работающих с мультиязычными материалами.
Для работы модели предусмотрена стандартная среда развертывания: Linux, Python версии 3.12 и выше, CUDA 12.8 и PyTorch 2.7.1. Разработчики рекомендуют использовать графический процессор NVIDIA уровня H100 на 80 ГБ видеопамяти, что позволяет обрабатывать крупные наборы данных и сложные документы без заметных задержек. Для установки модели требуется около 6 ГБ дискового пространства.

Пайплайн ИИ-модели HunyuanOCR. Источник: .
Выводы
HunyuanOCR становится новым участником тусовки мультимодальных моделей для распознавания текста, предлагая доступность, универсальность и производительность в одной обертке. Благодаря продуманной архитектуре, широким языковым возможностям и способности работать в формате сквозного анализа, модель способна изменить стандарты OCR-индустрии и расширить доступность высокоточных мультимодальных систем даже при развертывании в системах с ограниченными ресурсами.
