Технология EMFASYS объединит Ethernet RDMA и CXL для создания пулов памяти в ИИ-системах
Введение
Компания Enfabrica представила технологию EMFASYS, объединяющую Ethernet RDMA и CXL для формирования пулов памяти, предназначенных для использования в серверных стойках на базе ИИ-ускорителей. Решение способно снизить нагрузку на высокоскоростную память HBM в GPU, повышая общую эффективность системы.
Подробнее о EMFASYS
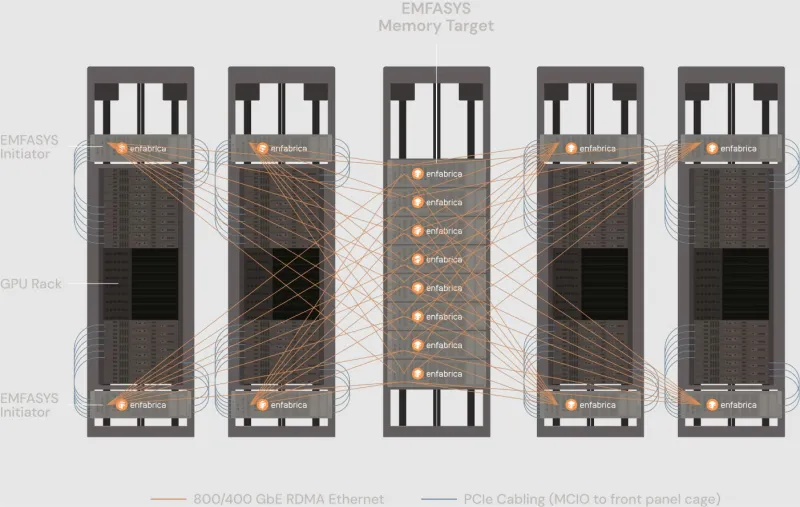
Компания Enfabrica, основанная в 2019 году, предлагает платформу ACF на базе собственных ASIC-чипов, использующих интерфейс CXL. Платформа обеспечивает прямое соединение любой комбинации GPU, CPU, DDR5 CXL и SSD-накопителей, а также предоставляет высокоскоростной интерконнект с пропускной способностью 800GbE. Компания разработала собственный чип ACF SuperNIC (ACF-S) для создания высокопроизводительных сетей внутри GPU-кластеров для разработки искусственного интеллекта. В рамках использования технологии EMFASYS, специализированный пул памяти подключается к GPU-серверам через коммутаторный чип ACF-S с пропускной способностью 3,2 Тбит/с, интегрирующий PCIe/CXL и Ethernet. Поддерживаются интерфейсы 800GbE, 400GbE и 100GbE, 32 сетевых порта и 160 линий PCIe. Могут использоваться до 144 линий CXL 2.0, обеспечивая доступ к 18 ТБ памяти DDR5 с перспективой расширения до 28 ТБ. Вместо копирования данных между чипами, Enfabrica применяет единый SuperNIC, представляющий память как целевое RDMA-устройство для ИИ-приложений. Высокая пропускная способность достигается распределением операций более чем по 18 каналам в системе. Время задержки при операциях чтения измеряется в микросекундах. Программный стек на основе InfiniBand Verbs обеспечивает массовую параллельную передачу данных с агрегированной полосой пропускания между GPU-серверами и DRAM через группы сетевых портов 400/800GbE.

Схема работы чипа ACF-S с технологией EMFASYS для расширения пулов памяти. Источник: .
Выводы
Компания Enfabrica подчеркивает, что их решение крайне покажет себя крайне эффективно в условиях экспоненциального роста нагрузок, которые создаются посредством развития генеративного, агентного и рассуждающего ИИ. Зачастую таким приложениям требуется в 10–100 раз больше вычислительных ресурсов на запрос, чем для LLM прошлого поколения. Перегруженная память HBM приводит к простаиванию дорогостоящих GPU-ускорителей. Технология EMFASYS решает эту проблему через расширение пулов памяти, обеспечивая более полную загрузку GPU и заявленную экономию до 50% на токен в расчете на одного пользователя.
