SiFive представила второе поколение ядер Intelligent на архитектуре RISC-V
Введение
Компания SiFive анонсировала новое семейство CPU-ядер Intelligent второго поколения, разработанных на базе архитектуре RISC-V. В линейку вошли новые типы ядер X160 Gen 2 и X180 Gen 2, а также обновленные версии ранее выпущенных ядер X280 Gen 2, X390 Gen 2 и XM Gen 2. Эти решения созданы для оптимизации выполнения скалярных и векторных операция, а в случае серии XM — и матричных вычислений, что делает эти решения подходящими для выполнения современных ИИ-задач.
Подробнее о Intelligent RISC-V Gen2
Ядра второго поколения позволяют решать критически важные задачи внедрения ИИ, включая оптимизацию управления памятью и ускорение нелинейных функций. Ключевым нововведением в серии Intelligent X стала возможность функционировать в качестве блока управления ускорителем (ACU). Это позволяет ядрам SiFive обеспечивать базовые функции управления ускорителями через интерфейсы SiFive Scalar Coprocessor Interface (SSCI) и Vector Coprocessor Interface eXtension (VCIX). Это позволит упростить оптимизацию стека, освободив время и ресурсы разработчиков на введение инноваций. Кроме того, представленные ядра также сокращают трафик системной шины за счет локальной обработки данных непосредственно на кристалле, а также улучшают координацию выполнения задач в предобработке и постобработке. В области устранения узких мест, новые ядра RISC-V обеспечивают устойчивость к задержкам памяти и более эффективную организацию подсистемы памяти.

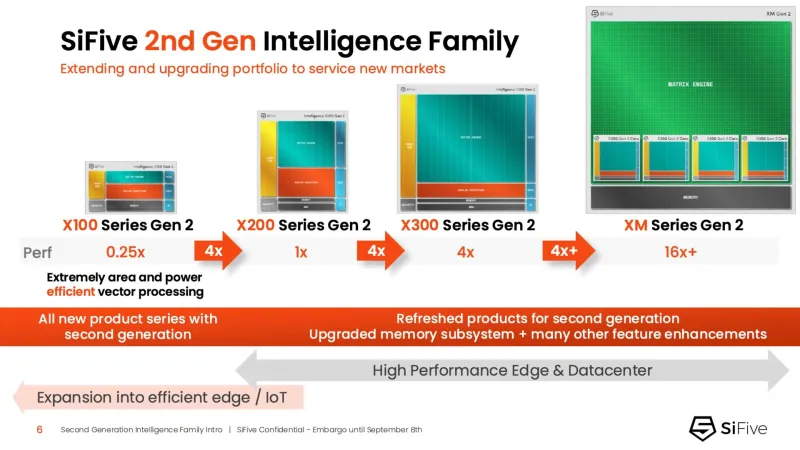
Описание RISC-V ядер SiFive Intelligent второго поколения. Источник: .
Технология Memory Latency Tolerance позволяет снизить задержку при загрузке данных. Скалярный блок, обрабатывающий инструкции, отправляет векторные команды в очередь VCQ, одновременно инициируя запрос к подсистеме памяти (кеш L2, L3, L4). Ранний запрос, отделенный от непосредственного выполнения, ускоряет получение данных и помещение их в передупорядочиваемую очередь VLDQ. Это позволяет заранее подготовить данные к моменту выполнения инструкций, тем самым обеспечивая выполнение векторной загрузки за один такт.

Возможности технологии Memory Latency Tolerance. Источник: .
Джон Симпсон, главный инженер SiFive, подчеркнул основное конкурентное преимущество новых RISC-V ядер: “Xeon, анонсированный на Hot Chips, поддерживает 128 невыполненных запросов — это топовый показатель для Xeon, а наш четырехъядерный процессор обрабатывает 1024”. Такая архитектура обеспечивает непрерывность потока обработки данных, эффективно предотвращая простои конвейера.
Еще одно существенное обновление — переход к новой иерархии кэшей. В предыдущем поколении данные из общего кэша L3 дублировались в частных кэшах L1/L2, что приводило к неэффективному использованию площади кристалла. Конструкция второго поколения исключает избыточное копирование, что, по словам Симпсона, дает прирост производительности в 1,5 раза по сравнению с первым поколением ядер при меньшей площади чипа.
SiFive также интегрировала новый аппаратный модуль для вычисления экспоненты. Если MAC-операции доминируют в ИИ-нагрузках, то возведение в степень становится следующим узким местом. Например, в BERT LLM с ускоренным матричным движком операции softmax, включающие экспоненту, занимают более 50% вычислительных циклов. Благодаря программным оптимизациям SiFive сократила выполнение экспоненты с 22 до 15 циклов, а новый аппаратный блок уменьшает это до одной инструкции, сокращая общее время выполнения до пяти циклов.

Описание аппаратного конвейерного экспоненциального блока в ядрах Intelligence. Источник: .
Программный стек для семейства Intelligence Gen 2 поддерживает масштабируемость. В серии XM среда выполнения машинного обучения уже распределяет нагрузки между несколькими кластерами XM на одном кристалле. Однако масштабирование за пределы одного чипа требует дальнейшего развития библиотеки межпроцессного взаимодействия (IPC).
Флагманские ядра X160 Gen 2 и X180 Gen 2 могут быть настроены для работы под управлением ОС в реальном времени. 32-битное ядро X160 оптимизировано для энергоэффективности и использования в средах с жесткими ограничениями по площади, тогда как 64-битное X180 обеспечивает более высокую производительность и лучше интегрируется с крупными подсистемами памяти.

Описание ядер SiFive Intelligence серии X100. Источник: .
X160 оснащается кэшем до 200 КиБ и памятью до 2 МиБ. Помимо промышленного применения, ядро может использоваться в потребительских устройствах, таких как фитнес-трекеры, а также в системах с несколькими ИИ-ускорителями для управления чипами и защиты прошивки. Благодаря двум встроенным кэшам с общей емкостью свыше 4 МиБ (мебибайт), ядро X160 отлично подходит для работы с большими объемами данных, обучения ИИ-моделей и использования в оборудовании мощных дата-центров.

Описание ядер SiFive Intelligence X280. Источник: .
Ядро X280 ориентировано на потребительские устройства, например, гарнитуры дополненной реальности, а X390 может применяться в автомобилях и инфраструктурных системах. Последнее выполняет векторную обработку в четыре раза быстрее X280.

Описание ядер SiFive Intelligence X390. Источник: .
Выводы
Все пять продуктов семейства Intelligence Gen 2 уже доступны для лицензирования. Выход первых чипов на основе новых ядер SiFive ожидается во втором квартале 2026 года. SiFive также сообщила, что два ведущих американских производителя полупроводников уже лицензировали серию X100 до ее публичного анонса. Одна компания будет использовать скалярно-векторное ядро SiFive в сочетании с матричным движком в качестве блока управления ускорителем, а вторая — применять векторный движок в качестве автономного ИИ-ускорителя.
