Recursive Language Models — инференс ИИ с неограниченным контекстом без потери качества
Введение
Независимые разработчики из Китая предложили концепцию Recursive Language Models (RML) — особую стратегию инференса ИИ, при которой языковая модель может разбивать задачу на части и рекурсивно обращаться к себе или другим моделям, прежде чем выдавать окончательный ответ. Это позволяет работать с неограниченно большим контекстом и смягчать эффект “context rot” (снижение качества при длинном контексте).
Подробнее о Recursive Language Models
В одной из реализованных версий RLM языковая модель работает в среде Python REPL, где весь контекст загружается как переменная. Модель может выполнять подзапросы к себе (или к отдельной компактной модели) для обработки частей контекста, комбинировать их, а затем выдавать окончательный ответ. Метод протестировали в двух бенчмарках:
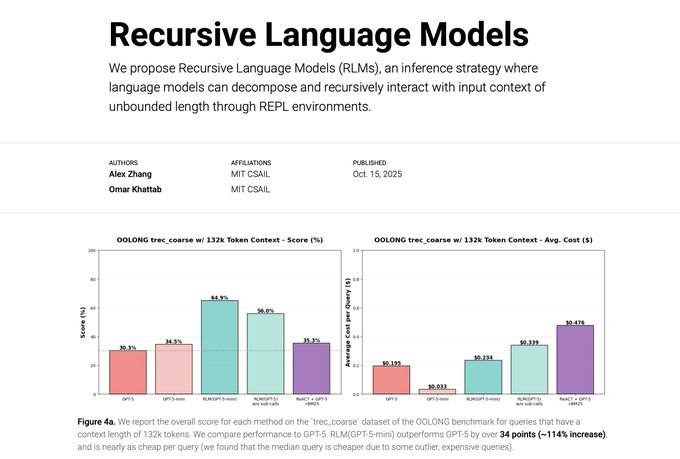
- OOLONG benchmark — задачи, требующие точного извлечения из очень длинного контекста. RLM с GPT-5-mini показывает более чем двукратное улучшение по сравнению с GPT-5, оставаясь при этом экономически конкурентоспособным решением.
- Deep Research / BrowseComp-Plus — задачи с множеством документов, где ответ разбросан по нескольким источникам. RLM лучше справляется с масштабируемостью контекста, сохраняя производительность при работе с гораздо большим объемом данных.

Результаты тестирования технологии RLM в связке с GPT-5. Источник: .
Разработчик также создает дополнительные стратегии оптимизации RLM:
- Peek / Grep — посмотр части текста, поиск по ключевым словам или шаблонам;
- Chunking / Recursion — разбиение контекста на части и запуск подзапросов;
- Суммаризация — объединение информации из частей перед окончательным ответом.
Несмотря на все преимущества RLM, в данный момент технология имеет ряд ограничений, например, в данный момент отсутствует оптимизация скорости инференса, рекурсивные вызовы блокируют кэширование префиксов, вызов API может стоить очень дорого, а глубина рекурсии в экспериментах ограничена 1 уровнем (основная модель не может вызывать другие RLM).

Схема работы технологии RLM. Источник: .
Выводы
Разработчик подчеркивает, что RLM — это не просто новый способ создания агентов и не просто методы суммаризации ИИ, а попытка передать модели контроль над управлением огромным контекстом: модель будет решать сама, как разбивать контекст и какие подзапросы делать. В будущем эта технология может обрести огромный потенциал использования при инференсе топовых языковых моделей, значительно расширяя их возможности и общую производительность.
