Qwen3-ASR и Qwen3-ForcedAligner: Alibaba усиливает позиции open-source ASR
Введение
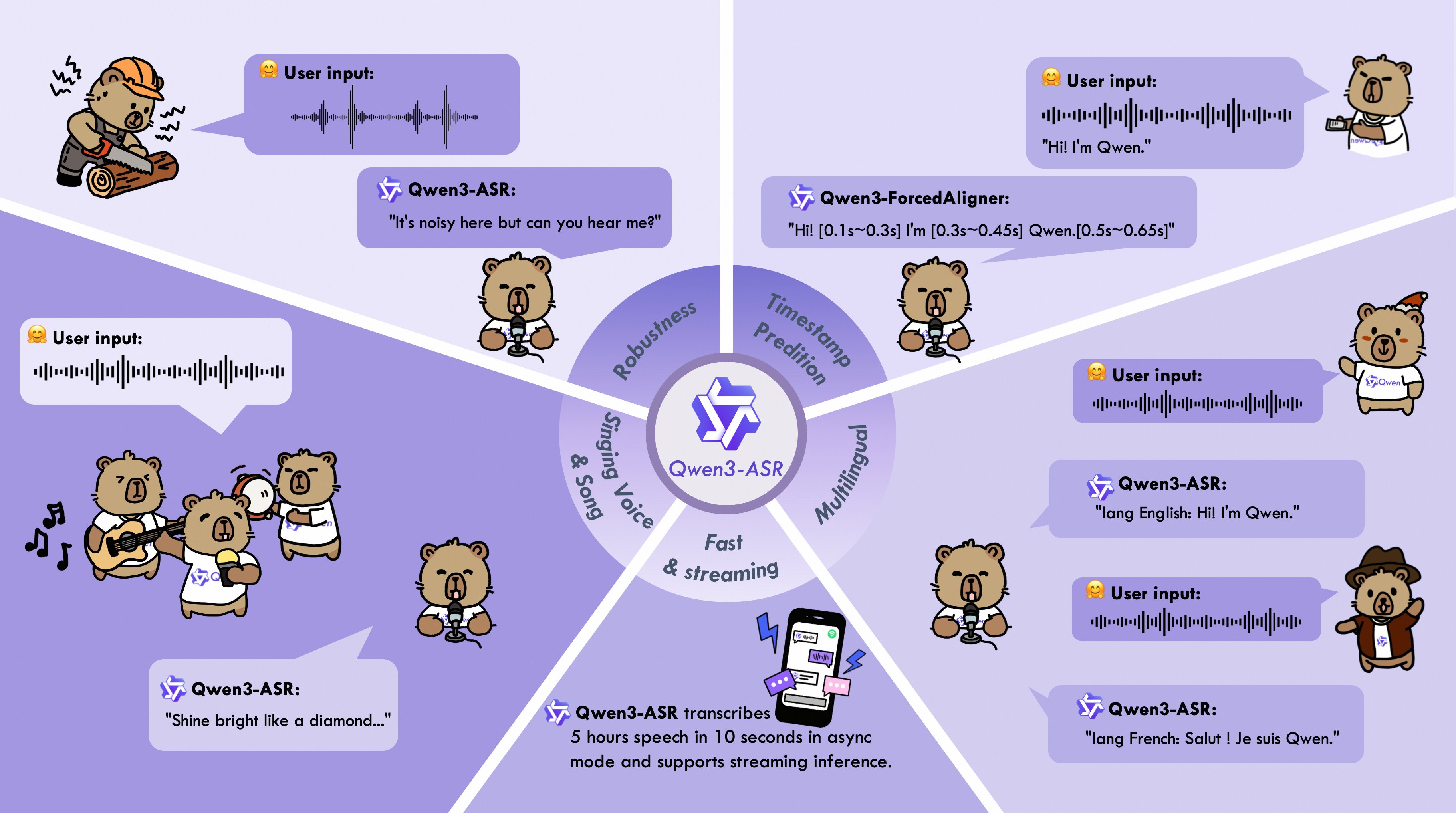
Команда Alibaba объявила об открытии исходного кода и весов Qwen3-ASR и Qwen3-ForcedAligner — новой линейки моделей для автоматического распознавания речи. Релиз ориентирован не только на достижение высоких позиций в академических бенчмарках, но и на реальные сценарии использования: потоковое распознавание голоса, высокую параллельность, работу со сложными диалектами и устойчивость в сложных акустических условиях. Все модели распространяются под лицензией Apache 2.0, что делает их пригодными для коммерческого и исследовательского применения.
Подробнее о Qwen3-ASR и Qwen3-ForcedAligner
Линейка Qwen3-ASR включает две универсальные модели — Qwen3-ASR-1.7B и Qwen3-ASR-0.6B, построенные на базовой модели . Они поддерживают распознавание речи и автоматическое определение языка для 52 языков, включая русский, диалекты китайского и английского. Обе модели работают как в оффлайн-режиме, так и в потоковом формате, используя единый инференс-контур, и способны обрабатывать аудиофрагменты длительностью до 20 минут без разбиения на части.

Архитектура модели Qwen3-ASR. Источник: .
Старшая модель Qwen3-ASR на 1,7 млрд параметров позиционируется как самая точная open-source ASR-модель на текущий момент. Во внутренних и публичных тестах она стабильно превосходит Whisper-large-v3 от OpenAI и демонстрирует сопоставимое, а в ряде сценариев и лучшее качество по сравнению с проприетарными API, включая GPT-4o Transcribe и решения Gemini. Особенно заметно преимущество в многоязычных наборах, китайских диалектах и сложных условиях — низком SNR, детской и пожилой речи, а также при распознавании поющего голоса с фоновой музыкой.

Производительность ИИ-модели Qwen3-ASR-1.7B. Источник: .
Более компактная модель Qwen3-ASR-0.6B ориентирована на высочайшую скорость. При меньшем размере она обеспечивает крайне низкую задержку и высокую пропускную способность: среднее время до первого токена составляет около 92 мс, а в асинхронном онлайн-режиме при параллельности 128 потоков модель способна расшифровывать до 2000 секунд речи за одну секунду вычислений. Это делает ее оптимальным вариантом для серверных ASR-сервисов, контакт-центров и потоковой аналитики.
Отдельно Qwen представила Qwen3-ForcedAligner-0.6B — неавторегрессионную модель принудительного выравнивания, использующую LLM-подход для предсказания временных меток. Она поддерживает 11 языков и работает с аудио длительностью до 5 минут, обеспечивая более высокую точность таймстемпов по сравнению с Nemo-Forced-Aligner, WhisperX и Monotonic-Aligner.
Вместе с моделями опубликован полноценный стек для инференса, включающий пакетную обработку на базе vLLM, асинхронное обслуживание, потоковый режим и инструменты для прогнозирования временных меток. Это превращает Qwen3-ASR не просто в набор весов, а в готовую к эксплуатации ASR-платформу.
Выводы
Открытие исходного кода Qwen3-ASR и Qwen3-ForcedAligner заметно усиливает экосистему open-source ASR. Qwen3-ASR-1.7B закрепляется как эталон точности среди открытых моделей, тогда как версия 0.6B закрывает нишу высокопроизводительных решений с низкой задержкой. Добавление мощного ForcedAligner расширяет сценарии использования — от дообучения с тонкой настройкой до мультимодальных пайплайнов.
