Parallel-R1: революционная система, обучающая ИИ мыслить параллельно
Введение
Команда исследователей Zhengkid представила первый в мире ИИ-фреймворк использующий обучение с подкреплением (Reinforcement Learning, RL) для формирования способности параллельного мышления у больших языковых моделей. Система получила название Parallel-R1 и, по словам разработчиков, позволяет моделям одновременно исследовать несколько путей рассуждений при решении задач, а затем объединять их в итоговый, сложный ответ.
Подробнее о Parallel-R1
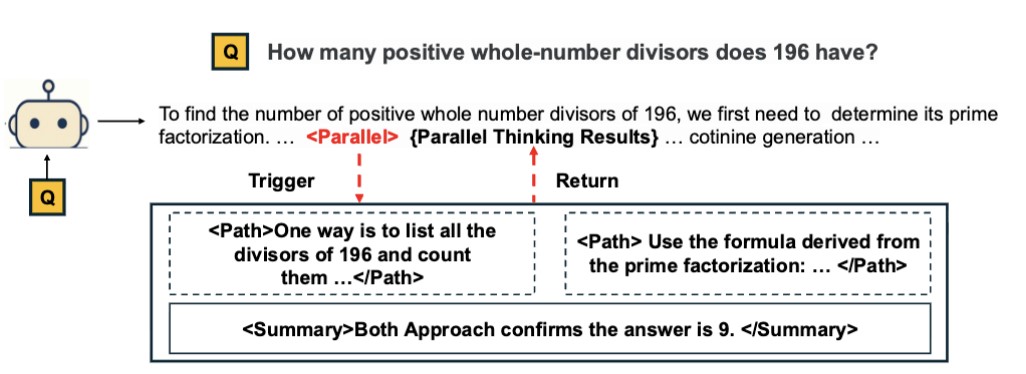
Разработчики Parallel-R1 отмечают, что параллельное мышление представляет собой инновационный подход к расширению когнитивных возможностей больших языковых моделей через одновременное исследование множественных путей размышления. Реализовать такой функционал с помощью традиционных методов обучения практически невозможно, поскольку они базируются на использовании системы supervised fine-tuning (SFT), в основе которой лежат синтетические данные — такая структура лишь симулирует информацию, а не приводит настоящие данные, улучшая когнитивные функции LLM.
Метод обучения с подкреплением Parallel-R1, использующий особый набор данных Parallel-GSM8K, позволяет преодолеть это ограничение, наделив активировав функцию параллельного мышления при решении сложных практических задач. Сама по себе технология обучения с подкреплением не нова, но метод исследователей из КНР использует прогрессивную учебную программу, которая целенаправленно решает проблему "холодного старта" при обучении параллельным стратегиям размышления. Кроме того, исследователи также внедрили особую систему чередовая поощрений в процесс обучения RL, при которой поощряется только точность, а за правильные ответы, полученные с помощью параллельного мышления, начисляются дополнительные баллы. Методика реализуется в два этапа: сначала применяется SFT для данных, сгенерированных для выполнения более простых задач, чтобы развить базовую способность к параллельному мышлению, а затем осуществляется переход к RL для изучения и обобщения этого навыка при работе со сложными задачами.

Шаги бучения по методу Parallel-R1. Источник: .
Тестирование в различных математических бенчмарках, таких как MATH, AMC23и AIME, показали, что метод Parallel-R1 успешно развивает способность к параллельному мышлению, обеспечивая повышение точности на 8,4% по сравнению с моделями, использующими последовательное мышление и обученными на сложных задачах через базовый RL. В тесте AIME2025 прирост эффективности составил 42,9%. Анализ результатов показал, что на начальных этапах модель использует параллельное мышление как инструмент исследования, тогда как на поздних стадиях эта же способность применяется для многоперспективной валидации множества решений.

Результаты тестирования в математических бенчмарках моделей, обученных через метод Parallel-R1. Источник: .
Разработчики планируют представить две собственные языковые модели, использующие метод обучения Parallel-R1 — Seen и Unseen, в которых используются новые архитектурные компоненты, такие как внимание к пути в окне и идентификатор позиции в мультивселенной. Исходный код новой модели обучения ИИ и нейросетей Seen и Unseen, в ближайшее время будет доступен на GitHub.

Шаги обучения по методике Parallel-R1. Источник: .
Выводы
Zhengkid совершили настоящую революцию в мире искусственного интеллекта, наделив нейросети навыком параллельного мышления. Благодаря этому, большие языковые модели больше не будут ограничиваться одной перспективой во время процесса размышления, предоставляя в разы более точные ответы, сгенерированные путем анализа разных аспектов запроса.
