AMD-HybridLM: новое семейство гибридных LLM
Введение
Компания AMD представила семейство новых компактныъ нейросетей, основанных на принципиально новом, гибридном подходе создания языковых моделей — AMD-HybridLM. Внутренние тесты показывают, что семейство AMD-HybridLM демонстрирует непревзойденный баланс между точностью и требованиями к системным ресурсом, что позволяет использовать их в устройствах с ограничениями по объему VRAM и TDP.
Подробнее о AMD-HybridLM
AMD считает, что традиционные модели-трансформеры сталкиваются с проблемами квадратичной сложности механизма внимания и большими требованиями к KV-кэшу. В высокопроизводительных ИИ-системах эти параметры не так критичны, однако в системах периферийных вычислений все это приводит к значительному увеличению задержек.

Сравнение точности, объема KV-кэша и пропускной способности инференса моделей AMD-HybridLM-8B с Llama-3.1-8B и MambaInLlama-8B-50%. Источник: .
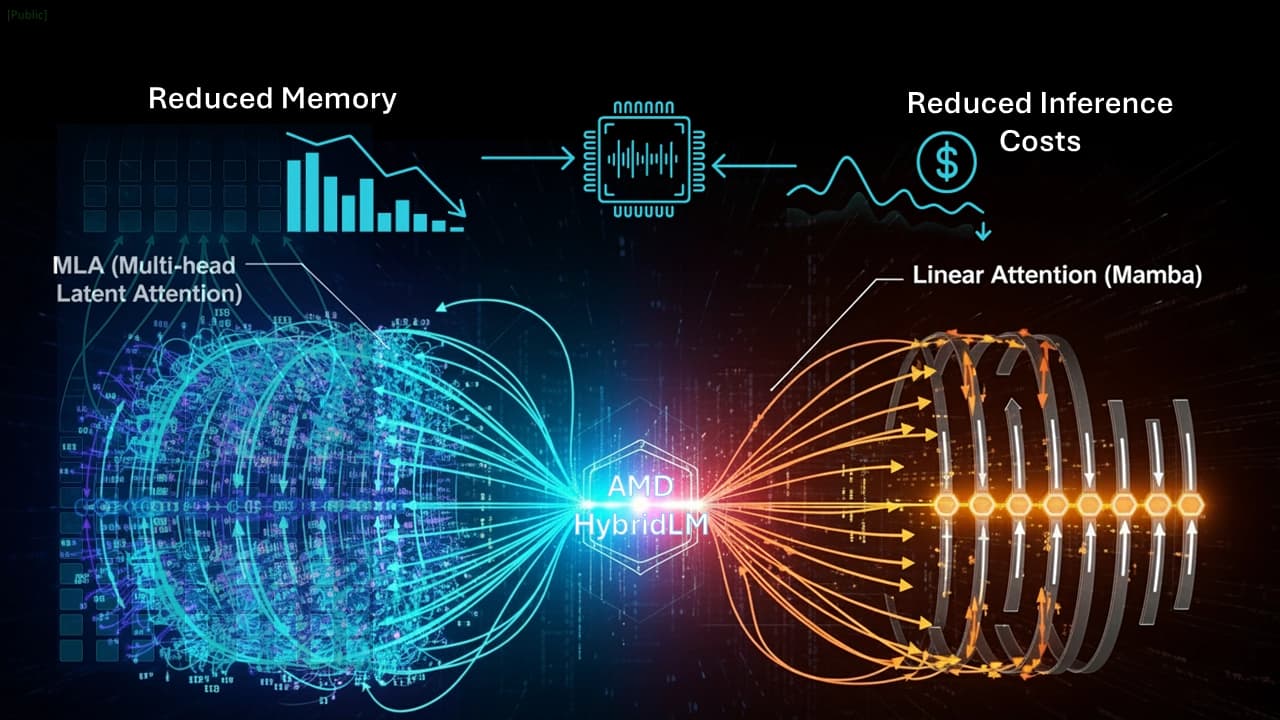
Чтобы решить эти проблемы, AMD предлагает практичное и эффективное решение в лице семейства гибридных моделей AMD-HybridLM (1B, 3B и 8B), созданных на базе предобученных трансформеров без использования полного переобучения. Архитектура новых нейросетей сочетает два ключевых компонента: механизмы Multi-Latent Attention (MLA) и Mamba2, что позволяет значительно сократить потребление памяти и затраты на инференс без компромиссов в производительности.
Гибридная комбинация слоев MLA, которые сжимают механизм внимания, и Mamba2 (базируется на State Space Models), которые устраняют необходимость в использовании KV-кэша, обеспечивают снижение расхода VRAM, увеличивают контекстное окно, при этом полностью сохраняя высокий уровень производительности. Кроме того, AMD применяет усовершенствованную инициализаци, промежуточную дистилляцию слоев и интеллектуальный выбор слоев SMART, что увеличивает эффективность дообучения LLM. Благодаря этим архитектурным доработкам, модели демонстрируют конкурентоспособную или повышенную производительность при значительно меньшем размере KV-кэша и повышенной пропускной способности инференса.

Тестирование моделей AMD-HybridLM без использования обучающих данных в бенчмарке LM Harness Eval по восьми базовым ИИ-задачам. Источник: .
Семейство моделей AMD-HybridLM включает семь конфигураций с различной степенью сжатия KV-кэша (от 12,8x до 49,8x) и оптимизированными параметрами обучения. Все модели семейства созданы на базе архитектуры Llama* (Llama* 3.2-1B-Instruct, Llama* 3.2-3B-Instruct и Llama* 3.1-8B-Instruct) и обучались на специализированных Llama* 3-ultrafeedback, orca_dpo_pairs и ultrafeedback_binarized lля прямой оптимизации предпочтений (DPO). с использованием 8 GPU AMD MI300.

Оценка использования VRAM при инференсе AMD-HybridLM и других ИИ-моделей на ускорителях AMD MI300. Источник: .
Выводы
Гибридные модели AMD-HybridLM демонстрируют наилучший баланс между точностью и эффективностью вывода, что делает их идеальным решением для развертывания на современном оборудовании, включая системы на базе ускорителей AMD Instinct MI300X, а также на периферийных системах с низким объемом VRAM. Вполне возможно, что благодаря AMD модели-трансформеры получат новый виток развития, превратившись в гибридные нейросети с оптимизированными возможностями инференса и демократичными требованиями к вычислительным ресурсам.
