Мультимодальный ИИ: новое слово в нейронных сетях
Источник: .
Содержание:
- Введение
- Почему мультимодальный ИИ становится популярным?
- Чем мультимодальные ИИ отличаются от традиционных?
- Обработка различных типов данных
- Взаимодействие между модальностями
- Архитектурные различия
- Вычислительная сложность
- Крупные мультимодальные проекты
- В чем реальная польза от мультимодальных ИИ?
- Бесплатные мультимодальные ИИ
- Заключение
Введение
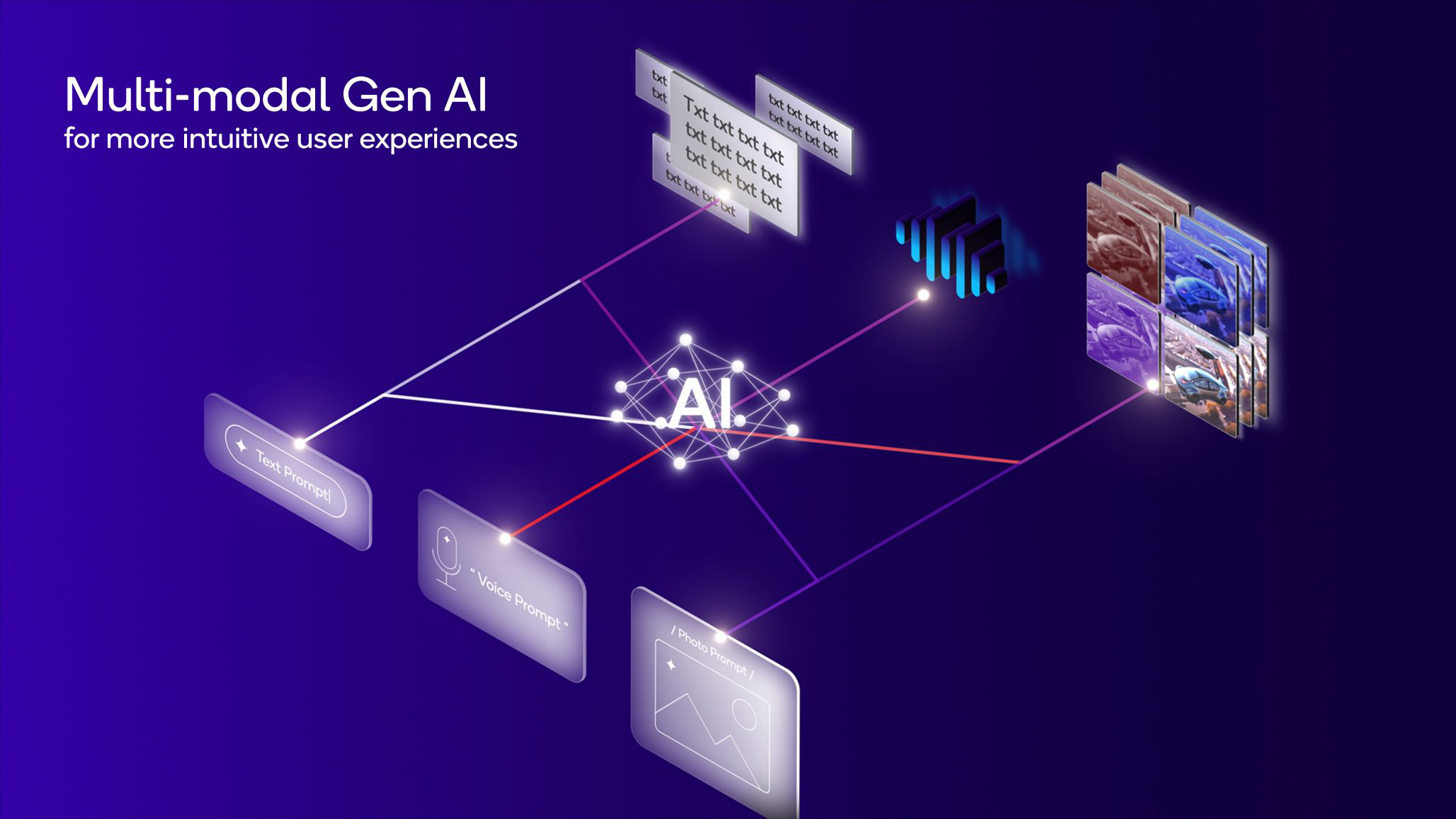
Мультимодальный искусственный интеллект – это инновационное решение в сфере ИИ, которое способно в каждый момент времени работать с информацией из различных источников, также именуемых как модальности. На фоне классических моделей, работающих лишь с одним типом данных, такие нейросети гораздо глубже и точнее понимают окружающий мир.
Под модальностью в контексте этой статьи понимается тип данных, который система получает и интерпретирует для выдачи результата. Возможность совмещения нескольких типов данных позволяет мультимодальным ИИ моделям более точно интерпретировать и решать сложные задачи, требующие понимания информации из разных форматов. В этом их главное преимущество.
В числе наиболее часто используемых модальностей для мультимодальных ИИ встречаются такие:
- текст: естественные языки в виде предложений, абзацев и различных текстовых данных;
- изображения: визуальные данные, включая фотографии, схемы, графику и символы;
- видео: последовательности изображений, в том числе сопровождаемые звуком;
- аудио: звуковые данные, включая речь, музыку и другие звуковые сигналы.
Кроме того, мультимодальный искусственный интеллект может воспринимать сенсорные данные, которые поступают от GPS, акселерометров и других устройств, воспринимающих внешнюю среду.

Демонстрация работы мультимодального ИИ Vertex AI Gemeni в ходе которого модель успешно распознала еду на фотографии и подготовила подробный рецепт приготовления. Источник: .
Почему мультимодальный ИИ становится популярным?
Популярность мультимодального искусственного интеллекта продолжает стремительно расти за счет его гибкости и эффективности в решении сложных задач, для качественного выполнения которых нельзя обойтись без взаимодействия с различными видами входной информации.
Увеличению востребованности технологии способствуют в том числе следующие факторы:
- Рост объемов разносторонних данных. Классические ИИ, работающие с одним видом данных, не способны полностью использовать потенциал массивов данных. Это значительно ограничивает их возможности в специфических задачах.
- Повышение вычислительных возможностей. Мощные графические процессоры сделали возможным обучение и использование мультимодальных моделей на больших объемах данных.
Вот лишь несколько популярных примеров задач, которые уже решаются мультимодальными ИИ:
- Автоперевод видео с субтитрами. Мультимодальный ИИ может анализировать аудио и видео вместе с субтитрами для точного перевода, учитывая жесты и мимику.
- Поиск по изображениям и тексту. ИИ позволяют пользователям находить информацию, сочетая текстовые запросы с изображениями, что особенно полезно в сфере продаж.
- Диагностика в медицине. Работающие с различными видами информации модели могут анализировать рентгеновские снимки и текстовые записи из медицинской карты пациента для более точных диагнозов.
Мультимодальный искусственный интеллект – это не просто очередной тренд в ИИ, а ключевая технология, которая открывает перед нами возможности более глубокого и комплексного анализа. С каждым годом эта отрасль продолжает быстро развиваться.

По мнению Google мультимодальный ИИ может помочь создавать новый уникальный контент на базе уже имеющихся данных за счет его расширенных возможностей по обработке различных типов информации. Источник: .
Чем мультимодальные ИИ отличаются от традиционных?
Мультимодальные(MLLM) и традиционные большие языковые модели (LLM) – это два разных подхода к обработке и анализу данных, хотя оба варианта базируются на нейронных сетях. Основное различие между ними заключается в том, как они обрабатывают данные и какие задачи могут решать. В этом разделе мы рассмотрим ключевые различия между технологиями.
Обработка различных типов данных
Большие языковые модели LLM, такие как GPT-3 или BERT, разработаны для работы исключительно с текстом. В их сфере компетенции лежат такие задачи, как проведение анализа, создание текстовых массивов, перевод текстового материала с одного языка на другой, суммаризация. Однако этим их функционал ограничен.
Мультимодальные ИИ может исследовать изображение и приведенное пользователем текстовое описание к нему одновременно, обеспечивая более глубокое понимание контекста и более точный анализ поступающей на вход информации.
Взаимодействие между модальностями
Традиционные LLM ограничены текстовой модальностью, поэтому они могут работать только с линейными зависимостями внутри текстовых данных. Это значит, что LLM не могут анализировать взаимосвязи между текстом и другими видами информации, например изображениями и звуком.
Мультимодальные модели, напротив, могут выявлять сложные связи между разной информацией. Взаимодействие между модальностями делает такие модели полезными в более сложных сценариях, где информация, полученная из разных источников, органично дополняет друг друга.

Схематичное представление интерпретации данных в мультимодальном ИИ. ИИ репрезентует текстовую и визуальную информацию в векторы, а впоследствии обрабатывает их в “привычном” формате совместно. Источник: .
Архитектурные различия
Архитектура традиционных LLM базируется на обработке последовательности токенов в тексте. Она обучается предсказывать следующий токен в последовательности или выполнять задачи, связанные с пониманием текста (например, классификация или извлечение информации). В основном такие модели используют трансформеры, которые справляются с задачами обработки естественного языка, но не могут напрямую работать с визуальными или другими типами данных.
Мультимодальные архитектуры, напротив, включают несколько разноплановых модулей. Например, в модели CLIP используется текстовый и визуальный модуль, которые объединяются для совместного обучения и анализа. Эти модули могут быть отдельными частями одной сети или работать параллельно, интегрируя результаты для получения более полной картины. Некоторые модели (тот же GPT-4) развивают свои возможности, добавляя мультимодальные компоненты к уже существующим моделям, что расширяет их функционал.

Принцип действия псевдо мультимодального ИИ заключается в подключении специализированных движков для распознавания голоса и генерации изображений к существующим языковым моделям (LLM). Этот подход позволяет имитировать функционал мультимодальных систем, обеспечивая видимость интеграции различных типов данных. Однако "под капотом" такая система остается ограниченной в масштабируемости и не может обучаться на датасетах, отличных от текстовых, что существенно ограничивает её возможности. Источник: .
Вычислительная сложность
Поскольку традиционные LLM работают только с текстом, их вычислительная сложность зависит от размера текстовых данных и архитектуры модели. Они требуют значительных вычислительных ресурсов для обучения и использования, но их сложность ограничена только одной модальностью.
Мультимодальные модели значительно более сложны в вычислительном плане, так как они работают с различными типами данных, каждый из которых требует своей архитектуры для обработки. Это делает их обучение и внедрение более ресурсоемким процессом. Например, обработка изображений требует мощных графических процессоров (GPU), а объединение с текстовой информацией в значительной степени увеличивает объем необходимых вычислений.

Специализированные ускорители Nvidia Tesla для ускорения инференса и обучения мультимодального ИИ(MLLM).
Крупные мультимодальные проекты
Крупные компании и исследовательские лаборатории активно разрабатывают системы, способные обрабатывать и объединять данные из различных модальностей. В этом разделе мы рассмотрим несколько наиболее значимых проектов мультимодального ИИ и их вклад в развитие технологий.
OpenAI CLIP
Одна из первых крупных мультимодальных моделей, разработанных компанией OpenAI. Обучена на больших наборах данных, содержащих как изображения, так и текстовые подписи к ним. Главная особенность CLIP заключается в том, что она может связывать визуальные данные (изображения) с текстом, обучаясь распознавать их в контексте друг друга. Например, модель может получать текстовый запрос и возвращать изображение, которое наиболее точно соответствует описанию, или наоборот – проанализировать изображение и генерировать текстовые описания на его основе.
Особенность CLIP в том, что эта технология обучена на наборе информации, где текстовые описания и изображения даны в естественном виде, без предварительной разметки. Это позволяет быстрее масштабировать модель, обучая ее на больших объемах информации под более узкие задачи.

На картинке изображена схема работы модели CLIP: текст и изображения кодируются в векторные представления, затем сопоставляются для выполнения задач классификации изображений. Источник: .
GPT-4
Актуальная версия крупной языковой модели от все той же компании OpenAI, которая, в отличие от своих предшественников, обладает мультимодальными возможностями. В числе последних:
- Анализ изображений. GPT-4 может анализировать картинку на входе и интерпретировать ее содержание. Например, распознать объекты на фото, объяснить контекст изображения или ответить на вопросы, связанные с изображенным объектом.
- Генерация текста в ответ на загруженное пользователем изображение. Такой функционал уже оценили специалисты, которые занимаются генерацией описаний товаров для маркетплейсов, и этим возможности применения вовсе не ограничиваются.
- Комбинированный анализ текста и изображений. Модель способна принимать на вход как текст, так и изображение, создавая более сложные взаимодействия, такие как объяснение смыслов изображения или сравнение его с текстом.
Применений у модели много. Так, на базе GPT-4 создаются виртуальные ассистенты, способные помогать не только текстом, но и визуальными подсказками или объяснять смысл изображений.
Общение с полноценным ассистентом GPT4o позволяет достигнуть максимального уровня вовлеченности ИИ в виду получения ИИ дополнительной информации: видеопотока с камеры, аудиодорожки с микрофона и расширенных данных с всевозможных датчиков устройства. Источник openai.com
*Процесс общения с GPT4o
DALL-E
Мультимодальная модель от компании OpenAI была разработана специально для формирования изображений, отталкиваясь от запросов, указанных пользователем в текстовом формате. DALL-E генерирует оригинальные изображения, комбинируя элементы на основе описаний, заданных пользователем, и воплощая в реальность необычные визуальные запросы.
Пользователь вводит текстовое описание, после чего модель генерирует изображение, наиболее соответствующее этому описанию. DALL-E способна создавать картинки, комбинируя различные стили и элементы. Это может быть полезно для создания визуальных концепций. Кроме того, модель может не только создавать статичные изображения, но и видоизменять их в разных стилях.

Абстрактное изображение символизирующее тесную работу визуальной составляющей данных и текстовой в рамках DALL-E. Источник: .
В чем реальная польза от мультимодальных ИИ?
Технология изменила подход к решению сложных задач в самых разных сферах деятельности человека. Вот несколько примеров их успешного реального применения:
- Медицина. Искусственный интеллект помогает анализировать сложные медицинские данные, такие как рентгеновские снимки, MRI или текстовые записи пациентов, что улучшает диагностику и ускоряет процесс принятия решений врачами.
- Искусство и творчество. С помощью моделей типа DALL-E и CLIP художники, дизайнеры и создатели контента могут легко генерировать визуальные элементы по запросу, создавать уникальные изображения и воплощать креативные идеи на базе описаний.
- Инженерия. В инженерии мультимодальные ИИ используются для анализа чертежей и технических документов, и это позволяет инженерам быстрее разрабатывать и тестировать новые проекты, улучшать процессы проектирования и производства.
В образовательной сфере мультимодальные ИИ помогают создавать интерактивные обучающие платформы, где студенты могут одновременно взаимодействовать с текстом и изображениями.
Бесплатные мультимодальные ИИ
Прямо сейчас в открытом доступе есть мультимодальные ИИ, которые можно использовать на бесплатной основе для разработки новых приложений, проведения исследований или решения творческих задач. В этом разделе рассмотрим некоторые из наиболее популярных инструментов.
LLaMA 3.2* от Meta AI**
Модель, разработанная компанией Meta** для работы с естественным языком и мультимодальными данными. LLaMA 3.2* может обрабатывать как текстовые данные, так и изображения. Применения:
- Исследовательские проекты. LLaMA 3.2* активно используется в академических исследованиях, где требуется анализ мультимодальных данных, например, для обработки текстов и изображений в рамках научных публикаций.
- Автоматизация рутинных задач. Модель можно использовать в бизнесе для автоматизации анализа данных. Например, автоматически описывать визуальный контент или генерировать текстовые метаданные для поиска и структурирования информации.
- Креативные приложения. Благодаря возможности обработки изображений и текста, LLaMA 3.2* подходит для генерации креативного контента, в том числе для рекламы и маркетинга.
На текущий момент доступны две версии мультимодальных моделей – 11В и 90В, которые можно скачать на официальном сайте LLaMA*.

Благодаря повсеместному распространению инструментов для локального запуска ИИ - движков для инференса. Сегодня можно запустить Llama* прямо на персональном ПК. Однако стоит предусмотреть, чтобы ваш GPU располагал достаточным объемом видеопамяти для запуска модели.
Pixtral 12B от Mistral AI
Крупная мультимодальная модель, разработанная компанией Mistral AI. Она нацелена на широкий спектр задач, где требуется мультимодальный анализ и генерация, и предлагает уникальные возможности для исследователей и разработчиков без больших вычислительных ресурсов. Плюсы:
- Высокая точность обработки изображений и текста. Pixtral 12B может находить скрытые зависимости между текстовыми и визуальными данными, что делает ее полезной для поиска изображений, описания визуального контента и создания визуальных материалов.
- Масштабируемость и открытый доступ. Mistral AI предоставляет Pixtral 12B в свободном доступе для некоммерческого использования, что позволяет исследователям, стартапам и разработчикам легко интегрировать ее в свои проекты. Также она популярна у студентов.

Найти Pixtral 12B можно на платформе Hugging Face. Источник: .
Заключение
Не исключено, что в ближайшем будущем нас ждет еще более широкое разнообразие бесплатных мультимодальных ИИ, которыми можно пользоваться без каких-либо материальных вложений.
Вы можете начать экспериментировать с мультимодальным искусственным интеллектом прямо сейчас. Даже бесплатные модели предоставляют невероятные возможности для творчества и анализа, которые раньше были доступны только крупнейшим корпорациям. Экспериментируйте, исследуйте, создавайте новые решения для бизнеса или личных проектов.
*LLAMA — проект Meta Platforms Inc.**, деятельность которой в России признана экстремистской и запрещена
**Деятельность Meta Platforms Inc. в России признана экстремистской и запрещена
