Квантизация ИИ: что это такое и для чего нужно?
Содержание:
- Введение
- Принципы работы квантизации
- Зачем используется квантизация в ИИ?
- Минусы квантизации в ИИ
- Заключение
Введение
Квантизация в искусственном интеллекте (ИИ) – это метод оптимизации, позволяющий уменьшить размер и сложность моделей машинного обучения без заметной потери их производительности.
В современных системах ИИ, особенно тех, которые используются на устройствах с ограниченными вычислительными ресурсами, таких как смартфоны и IoT-устройства, квантизация играет ключевую роль. Она помогает ускорить работу моделей, сократить потребление энергии и памяти, что делает технологии ИИ доступными для широкого круга применений. Но все ли хорошо с этой технологией?
Принципы работы квантизации
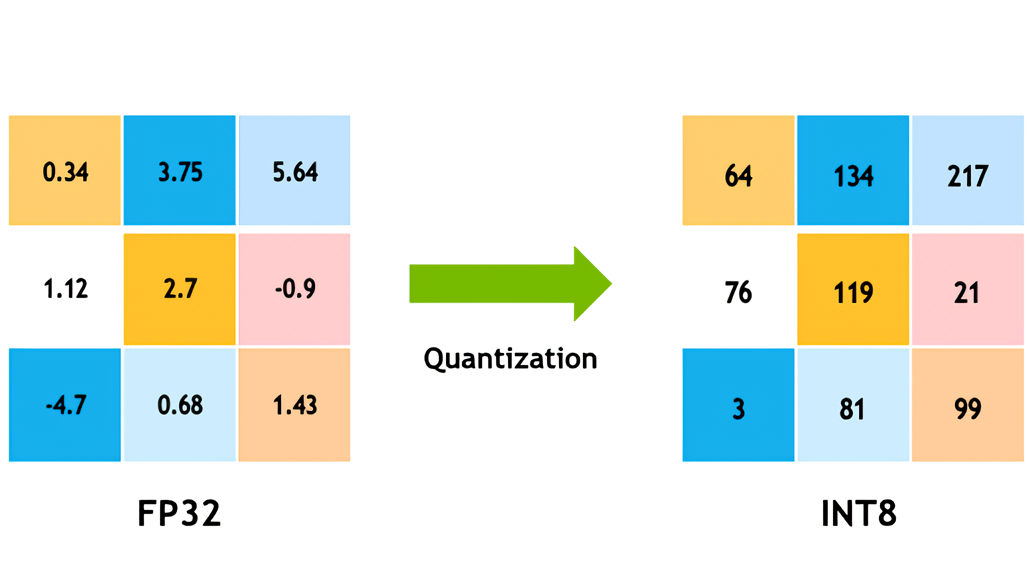
Квантизация (или квантование) – это процесс преобразования числовых значений в модели машинного обучения из высокоточных форматов с плавающей запятой (например, 32-битных FP32 или 64-битных FP64) в форматы с меньшей точностью, такие как FP8 с плавающей запятой или даже целочисленный INT8 (8-битные целые числа). Такое преобразование осуществляется с минимальными потерями точности модели благодаря тщательно спланированным алгоритмам.
Процесс квантизации моделей искусственного интеллекта включает в себя следующие действия:
- Анализ распределения данных. Сперва оцениваются диапазоны значений весов, активаций модели. От точности определения диапазона зависят результаты после округления.
- Нормализация. Подготовленные значения приводятся к единому стандартному диапазону, например, весам задаются границы от минимального до максимального значения.
- Округление. После нормализации значения округляются до ближайших целых чисел, которые могут быть эффективно обработаны доступными аппаратными средствами.
- Обратное преобразование. После вычислений результаты могут быть восстановлены до более точных форматов, если в этой задаче возникает практическая необходимость.
Хотя после квантизации модель может незначительно потерять в точности, выигрыш в скорости выполнения и снижении затрат на ресурсы может оказаться критически важным для ряда задач.

Сравнение между квантизированными и высокоточными представлениями различных типов данных. Изображение иллюстрирует как квантизация может сократить объем данных и вычислительных ресурсов, необходимых для работы с различными типами данных. Источник: .
Зачем используется квантизация в ИИ?
Квантизация в искусственном интеллекте играет важную роль в оптимизации моделей машинного обучения для выполнения на устройствах с ограниченными вычислительными ресурсами. Это особенно актуально в эпоху распространения мобильных устройств, интернета вещей (IoT) и облачных технологий, где скорость обработки, потребление энергии и памяти весьма критичны.
Оптимизация ресурсов
Современные модели глубокого обучения, в числе которых сверточные нейронные сети (CNN) или трансформеры, требуют значительных вычислительных мощностей для обработки внушительных объемов данных. Например, задачи компьютерного зрения или обработки естественного языка могут потребовать сотни миллиардов операций в секунду. Не каждый смартфон сможет это делать.
Квантизация помогает снизить эту нагрузку, сокращая количество операций с плавающей запятой, которые требуют больше вычислительных ресурсов. Преобразование “тяжелых” чисел с плавающей запятой FP32 в более “легкие” форматы FP4 или FP8 позволяет значительно ускорить выполнение моделей, так как операции с меньшей точностью выполняются быстрее и требуют куда меньше ресурсов.

Ускорители Tesla могут похвастаться кратной производительностью в форматах со сниженной точностью. Например H100 способен выполнять операции FP8 практически в 4 раза быстрее чем TF32 Tensor Core. Источник: .
Экономия памяти
Еще одно важное преимущество квантизации — значительное сокращение объема памяти, требуемого для работы с моделями. Веса и активации в модели машинного обучения обычно представлены числами с плавающей запятой FP32, каждое из которых занимает 4 байта. При квантизации эти значения могут быть преобразованы в менее ресурсоемкие форматы с меньшей точностью, такие как INT8, что снижает потребление памяти до 1 байта на число. Это позволяет уменьшить размер модели в четыре раза, что делает ее пригодной для развертывания на потребительских видеокартах или даже на портативных устройствах, таких как мощные смартфоны или планшеты.

Наглядная разница в потреблении VRAM в рамках модели LLAMA 3.2* 65B. Для запуска мощной не квантизированной версии потребуется мощный сервер с 4 дорогостоящими ускорителями Tesla H100, а для квантизированной версии в INT8 будет достаточно нескольких потребительских видеокарт RTX 4090.
Экономия энергии
Квантизация существенно снижает энергопотребление моделей машинного обучения, так как менее ресурсоемкие операции INT8/FP8/FP16 требуют меньше электроэнергии по сравнению с операциями с FP32/FP64. Это особенно критично для автономных систем, которые должны работать долго без подзарядки или имеют ограниченный запас энергии.
В мобильных устройствах, которые активно используют ИИ для обработки изображений или голосовых команд, квантизация позволяет увеличить время работы устройства без подзарядки.

LLama 3.2* также поставляется в варианте “легкой” или “портативной” модели для запуска на мобильных платформах. Источник: *.
Минусы квантизации в ИИ
Несмотря на значительные преимущества квантизации для оптимизации моделей искусственного интеллекта (ИИ), она также имеет свои недостатки, которые могут ограничить ее применение. Они связаны с тем, что квантизация изменяет внутренние представления весов и активаций моделей, что иногда может негативно сказаться на их точности, стабильности. Рассмотрим основные минусы.
Потеря точности
Преобразование весов и активаций в менее точные форматы неизбежно приводит к потере точности. Это критично для моделей, которые изначально требовали высокоточных вычислений для достижения максимальных результатов, таких как нейронные сети, которые работают с изображениями высокого разрешения или сложными временными рядами.
При квантизации часть информации теряется, так как значения округляются или нормализуются. В результате модель может хуже справляться с тонкими нюансами данных, что особенно заметно в сложных задачах, таких как анализ естественного языка, генерация текста, компьютерное зрение.
Не все модели машинного обучения одинаково хорошо переносят квантизацию. Простые модели, такие как линейные классификаторы или модели с небольшим количеством параметров, обычно квантизируются с минимальной потерей точности. Однако сложные архитектуры, такие как глубокие сверточные (CNN) или рекуррентные нейронные сети (RNN) страдают заметно сильнее.
Некоторые слои в таких моделях могут оказаться особенно чувствительными к снижению точности представления весов и активаций. Например, сверточные слои, которые извлекают детализированные признаки изображений, или рекуррентные слои, ответственные за обработку последовательностей, могут потерять в эффективности, если их веса округляются до целых чисел.

Наглядная разница падения качества визуализации изображения генеративным искусственным интеллектом вызванная черезмерной квантизацией. Источник: .
Проблемы с обучением
Хотя квантизация может применяться к уже обученным моделям, этот подход не всегда работает идеально. Некоторые модели могут сильно терять в точности после применения инструмента. Одним из решений является обучение с учетом квантизации, при котором округление интегрируется на этапе подготовки модели. Этот подход может минимизировать потери в точности.
Зависимость от архитектуры
Эффективность квантизации напрямую зависит от аппаратной архитектуры, на которой модель будет выполняться. На практике это означает, что не все устройства и процессоры одинаково хорошо поддерживают операции с целыми числами, особенно с низко разрядными форматами, такими как INT8. На некоторых аппаратных платформах (например, CPU без специализированных инструкций для целочисленных операций) выгоды от квантизации могут быть минимальными.
Кроме того, квантизированные модели часто оптимизируются для работы на конкретных устройствах, таких как графические процессоры (GPU), тензорные процессоры (TPU) или специализированные чипы нейронных вычислений (NPU). Если модель разрабатывается для универсальных платформ, таких как обычные процессоры, преимущества от квантизации могут быть значительно снижены.

Сегодня компании налаживают поставки специализированных микросхем ориентированных исключительно на вычисления связанные с обучением и инференсом ИИ. Ярким примером таковых TPU являются ускорители Intel Gaudi 3, демонстрирующие впечатляющую производительность в формате вычислений FP16. Источник: .
Ограниченная кроссплатформенность
Квантизация модели для одной платформы не всегда может быть легко перенесена на другую без адаптации. В зависимости от того, какие технологии и аппаратные средства используются, квантизированные модели могут требовать дополнительных усилий для портирования на разные устройства. Это создает дополнительную сложность для разработчиков, которые должны обеспечивать кроссплатформенную совместимость своих решений. Это требует дополнительных усилий для тестирования и оптимизации модели под каждую конкретную систему, что может замедлить процесс разработки приложений и в значительной степени увеличивает затраты на нее.
Заключение
Хотя квантизация даёт значительные преимущества, такие как снижение вычислительной нагрузки и экономия ресурсов, она также имеет ряд ограничений, которые могут сдерживать её применение. Тем не менее, это остаётся полезным инструментом при правильном подходе. Успешное использование квантизации требует учёта специфики поставленных задач и доступного аппаратного окружения. Применение квантования в моделях ИИ может значительно ускорить инференс без заметного снижения качества результатов, что делает этот метод столь востребованным в современных приложениях.
Что особенно важно, квантизация позволяет использовать мощные модели ИИ на более широкой гамме устройств, начиная от серверов и заканчивая мобильными устройствами, предоставляя более широкий доступ к возможностям искусственного интеллекта. Это открывает новые горизонты для внедрения ИИ в самых разных областях, что делает квантизацию одним из ключевых элементов в развитии современных технологий.
*LLAMA — проект Meta Platforms Inc.**, деятельность которой в России признана экстремистской и запрещена
**Деятельность Meta Platforms Inc. в России признана экстремистской и запрещена
