7 способов ускорить работу искусственного интеллекта и сделать его более лёгким
Источник:
Содержание:
- Введение
- Прядение
- Sparse Matrix Representation
- Sparse Coding
- Сжатие весов
- Сжатие и кодирование моделей
- Забывание маловажной информации
- Low-Rank Approximation
- Parameter Sharing
- Заключение
Введение
Современные модели искусственного интеллекта (ИИ) способны решать сложнейшие задачи: от распознавания изображений до обработки естественного языка. Однако их высокая точность зачастую требует огромных вычислительных ресурсов и памяти, что делает такие модели сложными для развертывания на мобильных устройствах. Например, на смартфонах и планшетах.
Один из способов упростить модели ИИ – это квантизация, которая уменьшает их размеры без значительного падения производительности. Но существуют и другие методы, которые позволяют добиться схожих результатов. Далее мы рассмотрим еще 7 популярных подходов к облегчению ИИ.
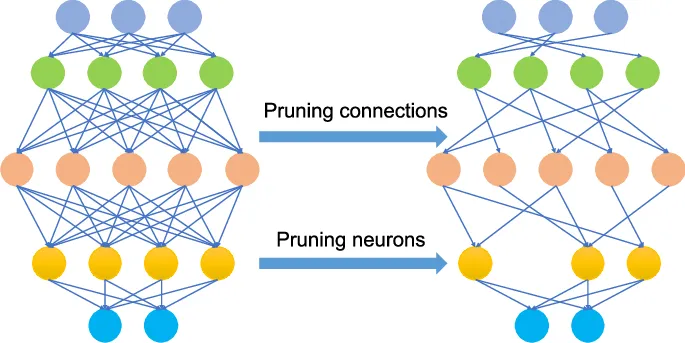
Прядение
 в deep learning")
Источник:
Прядение (или neural pruning) является одним из самых популярных методов уменьшения размера нейронных сетей. Его цель – сделать модель проще и легче за счет удаления части структуры, при этом не жертвуя точности.
В традиционной нейронной сети имеются миллионы, а иногда и миллиарды соединений (весов), связанных нейронами. Эти связи участвуют в передаче информации и обучении модели. Однако исследования показывают, что далеко не все эти связи критически важны для точности. Некоторыми связями можно просто пренебречь, и модель все равно будет выполнять свою задачу.
Процесс прядения заключается в том, чтобы проанализировать модель и убрать наименее значимые нейроны и связи в ее структуре. Это уменьшает как количество вычислений, которые модель должна сделать для обработки информации, так и общий объем памяти для ее работы.
Виды прядения
Прядение может проводиться по-разному, и в зависимости от выбранного метода можно добиться различных результатов:
- Прядение на уровне соединений. Удаляются отдельные связи между нейронами, которые имеют наименьшие веса. Такой метод применяется для больших сетей, где многие связи оказываются избыточными.
- Прядение на уровне нейронов. Удаляются целые нейроны, не вносят значительного вклада в работу модели. Этот подход полезен в глубинных нейронных сетях, где многие нейроны могут лежать малополезным грузом.
- Структурное прядение. Удаляются целые блоки или слои нейронной сети. Этот вариант помогает не только уменьшить количество весов, но и упростить саму архитектуру модели.
Метод прядения подбирается исходя из характеристик исходной модели и запросов к результату.
Sparse Matrix Representation

Источник:
Sparse Matrix Representation, или, по-другому, разреженные матрицы – это один из эффективных методов, используемых для оптимизации моделей искусственного интеллекта. Этот подход особенно полезен для уменьшения объема вычислений и сокращения объема памяти, который требуется для работы сложных нейронных сетей.
Чтобы понять, как работает Sparse Matrix Representation, представим, что модель хранит данные в виде огромных таблиц, где каждое число отражает силу связи между нейронами. Но вот интересная деталь: в таких таблицах множество чисел могут быть нулями, то есть никак не влиять на результат.
В классической нейронной сети каждая связь между нейронами представляется в виде веса, что создает огромные матрицы чисел. Однако на практике оказывается, что большинство этих весов не играют важной роли в обработке данных. Они либо слишком малы, либо вообще равны нулю. В случае разреженных матриц, основной задачей является игнорирование этих нулевых значений и фокусировка только на тех элементах, которые действительно важны. Другими словами, это попытка представить модель так, чтобы ресурсы использовались только для значимых данных.
Основное преимущество разреженных матриц в том, что они значительно сокращают количество вычислений, которые нужно выполнить модели для выполнения задачи. Когда сеть не обращает внимания на нулевые веса, она тратит меньше времени на обработку каждого сигнала, и это ускоряет ее работу. Особенно это важно, когда речь идет о нейросетях с миллионами параметров.
Sparse Coding

Источник:
Sparse Coding – это более сложное понятие, но его цель схожа с разреженными матрицами. Здесь акцент делается на то, чтобы представить информацию в более компактном и экономичном формате. Каждый объект можно описать с помощью набора базовых элементов, но лишь немногие из этих элементов будут использоваться для конкретной задачи. Таким образом, информация кодируется эффективнее, что уменьшает количество ресурсов для хранения и обработки данных.
Например, в области обработки изображений Sparse Coding может применяться для того, чтобы сократить количество данных, которые нужны для описания картинки. Вместо того чтобы сохранять каждую деталь изображения, система пытается выделить только ключевые элементы, которые дают полное представление о содержимом. Это помогает значительно уменьшить объем информации, которую нужно хранить, и делает обработку изображений более быстрой.
Концепция разреженности лежит в основе многих методов оптимизации ИИ. Она помогает снизить затраты на вычисления и сократить время, необходимое для обучения и работы модели. Этот подход особенно полезен в тех случаях, когда модель обучается на огромных наборах данных и содержит миллионы или даже миллиарды параметров.
Однако важно помнить, что применение разреженных матриц и разреженного кодирования должно быть продумано и аккуратно сбалансировано. Слишком агрессивное удаление нулевых значений или минимально значимых параметров может привести к тому, что модель потеряет важные данные и начнет выдавать неточные результаты.
Сжатие весов

Источник:
Сжатие весов (или weight pruning) – это процесс, при котором из модели удаляются незначительные веса. Напомним, что в контексте нейронных сетей под весами понимаются значения, которые определяют силу связи между нейронами. Когда сеть обучается, она настраивает эти веса, чтобы научиться лучше решать задачи. Однако не все веса в модели одинаково важны, и некоторые из них оказывают настолько малое влияние, что их можно убрать без ущерба для точности модели.
Основная идея сжатия весов заключается в том, чтобы обнулить или удалить те веса, которые имеют минимальное значение. Это позволяет существенно сократить количество параметров в ИИ. Модель после этого становится легче, так как ненужные параметры больше не требуют вычислений. Удаление незначительных весов не всегда приводит к падению точности. Правильная настройка сжатия позволяет сохранить высокую точность даже при сильном сокращении модели.
Процесс начинается с того, что модель сначала обучается как обычно, после чего проводится анализ ее весов. Если определенные из них близки к нулю, их можно обнулить или удалить. После этого модель проходит переподготовку, чтобы адаптироваться к новому состоянию и компенсировать возможные потери в точности. Это помогает восстановить эффективность модели после сжатия.
Практическое применение сжатия весов можно наблюдать в задачах, где необходимо развернуть модели ИИ на устройствах с ограниченными вычислительными мощностями. Например, для моделей распознавания голоса или изображений, развернутых на смартфонах, критически важно минимизировать размер и потребление ресурсов модели без существенного ухудшения точности.
Сжатие и кодирование моделей
Основной принцип сжатия и кодирования моделей заключается в том, чтобы найти способ более компактного представления данных и параметров. Для этого используются различные алгоритмы кодирования, которые позволяют упаковать модель в более компактную форму. Такие методы позволяют сохранить информацию, но при этом использовать меньше памяти для ее хранения.
Одним из самых известных методов кодирования является Хаффмановское кодирование. Этот алгоритм позволяет уменьшить объем данных за счет замены часто встречающихся элементов (например, весов в модели) на более короткие коды, а редких – на более длинные. В результате, когда модель хранится или передается, она занимает меньше памяти, что делает ее более легкой.
Кроме Хаффмановского кодирования используются и другие методы сжатия и кодирования:
- Квантование весов. Уменьшает точность представления весов, заменяя их высокоточными числами с плавающей запятой на более простые, например, целые числа. Это позволяет существенно уменьшить объем памяти, требуемый для хранения модели.
- Кодирование энтропии. Подобно Хаффмановскому кодированию, метод используется для оптимизации представления данных, минимизируя объем битов, необходимый для хранения часто встречающихся значений. Он активно используется в сжатии изображений.
- Факторизация матриц. Этот метод разложения больших матриц весов модели на несколько меньших матриц используется для того, чтобы снизить количество параметров, которые должны храниться. Модель сохраняет функциональность, но требует меньше памяти.
Перед применением методов кодирования и сжатия необходимо определить, какие параметры модели могут быть уменьшены или представлены в более компактном виде. Это может включать удаление ненужных весов или уменьшение числа битов для хранения каждого параметра. После этого применяется алгоритм кодирования, который переводит оставшиеся данные в сжатую форму.
Кодирование может быть использовано для улучшения безопасности моделей. Путем кодирования можно затруднить процесс обратного инжиниринга (восстановления исходных данных модели). Это может быть полезным в ситуациях, когда нужно защитить интеллектуальную собственность.
Забывание маловажной информации
Суть этого метода заключается в том, что знания большой модели (учителя) передаются более маленькой модели (ученику), которая затем способна выполнять те же задачи, но с меньшими ресурсами.
Сам процесс забывания состоит из нескольких шагов. Сначала обучается большая, часто слишком громоздкая и мощная модель, которая показывает высокую точность на сложных задачах. Она играет роль «учителя». Затем разрабатывается маленькая модель, которая должна стать ее «учеником». Эта ученическая модель намного проще и содержит меньше параметров, но ей предстоит усвоить важные знания, накопленные старшей версией в процессе ее обучения.
Маленькая модель обучается на тех же данных, что и большая, но при этом она использует также результаты (прогнозы) «учителя» в качестве дополнительного руководства. В результате такой ИИ способен воспроизводить точные результаты с меньшим количеством вычислений и памяти.
Забывание маловажной информации играет ключевую роль. В процессе обучения большая модель не только делает правильные предсказания, но и выявляет множество данных, которые не так важны для конечного результата. Ученическая модель наследует эти знания и «забывает» маловажную информацию.
Хотя забывание обладает многими преимуществами, есть и определенные сложности, связанные с этим методом. Одна из них – это выбор подходящей архитектуры для ученической модели. Она должна быть достаточно простой, чтобы оправдать цель уменьшения размеров, но при этом достаточно сложной, чтобы правильно понять знания, переданные учителем.
Еще одна сложность – правильный выбор данных и методов обучения. Если данные или прогнозы «учителя» не будут достаточно разнообразны или точны, ученическая модель может не достичь необходимой производительности.
Low-Rank Approximation
Источник: .
Метод основан на том, чтобы упростить большие матрицы весов в нейронной сети, разложив их на несколько меньших матриц с более низким рангом. В результате модель требует меньше вычислительных ресурсов и памяти для обработки данных, что делает ее легче и быстрее.
В нейронных сетях весовые матрицы играют ключевую роль, так как они определяют связи между слоями сети. Чем больше слоев и нейронов в модели, тем больше матриц весов необходимо для ее работы. В некоторых случаях эти матрицы могут содержать избыточную информацию, что приводит к увеличению объема данных, которые нужно обрабатывать. Это особенно актуально для глубоких нейронных сетей, которые могут иметь миллионы параметров.
Пример работы метода можно объяснить на аналогии с изображением. Представьте, что у вас есть картинка в высоком разрешении. Если вы попытаетесь ее сжать, можете потерять качество, но с правильным сжатием основные детали картинки останутся видимыми. Так же и с весами нейронной сети: хотя модель теряет часть избыточных данных, структура и значимые параметры остаются, что позволяет сохранить точность и снизить вес.
Основной принцип метода заключается в разложении матрицы весов на произведение двух или меньших матриц с более низким рангом. Они имеют гораздо меньше параметров, что снижает общую сложность модели.
С математической точки зрения, каждая матрица весов может быть представлена как набор данных, которые можно аппроксимировать с помощью меньшего числа базовых элементов. При этом, вместо хранения всей матрицы, модель сохраняет только основные компоненты, что значительно снижает ее объем.
Этот метод особенно актуален для таких приложений, как компьютерное зрение и обработка естественного языка, где нейронные сети должны работать с огромными объемами данных. Например, в задачах распознавания изображений модели могут состоять из тысяч или даже миллионов параметров, и разложение матриц весов с помощью Low-Rank Approximation помогает уменьшить эту сложность, сохраняя при этом качество распознавания на достойном уровне.
Метод часто используется вместе с другими техниками оптимизации, такими как прядение и квантизация. Например, после того как ненужные связи и веса были обрезаны, оставшиеся параметры можно аппроксимировать с помощью разложения на матрицы с низким рангом. Это дает возможность дополнительно уменьшить количество данных, подлежащих обработке.
Однако, как и любой метод оптимизации, Low-Rank Approximation имеет свои ограничения. Одним из главных рисков является возможность потери точности модели. При неправильном применении или слишком агрессивной аппроксимации модель может начать терять способность точно предсказывать результаты.
Еще одним вызовом является то, что не все части нейронной сети могут быть эффективно аппроксимированы. Некоторые слои модели могут содержать важные детали, которые нельзя упростить без потерь. Это требует тщательного анализа структуры модели перед облегчением ИИ.
Parameter Sharing
 в DL")
Источник: .
Parameter Sharing или совместное использование параметров – это метод оптимизации нейронных сетей, который позволяет существенно уменьшить количество уникальных параметров (весов) в модели за счет их многократного использования в различных частях сети.
Такой подход особенно полезен для больших моделей, где избыточное количество параметров может потребовать значительных вычислительных ресурсов и памяти. Совместное использование параметров помогает снизить сложность модели, что ускоряет ее работу и делает ее легче для развертывания на устройствах с ограниченными ресурсами.
Основная идея метода заключается в том, что некоторые параметры модели могут быть одинаково полезны в разных местах нейронной сети. В обычной нейронной сети каждому соединению между нейронами соответствует свой уникальный вес, который определяет силу связи.
Однако в некоторых архитектурах, таких как сверточные нейронные сети, одни и те же параметры (веса) могут использоваться многократно для разных областей входных данных. Это позволяет сети учиться на общих шаблонах и признаках, что уменьшает количество уникальных параметров.
Кроме того, Parameter Sharing помогает улучшить обобщающую способность модели. Поскольку одни и те же параметры используются для обработки различных частей входных данных, модель обучается выявлять общие шаблоны и закономерности, что помогает ей лучше справляться с новыми, ранее невиданными данными.
Например, в задаче распознавания объектов на изображениях модель сможет распознавать одинаковые признаки объектов, независимо от их положения в кадре. Это делает модель более устойчивой к изменению условий и более универсальной.
Этот метод особенно полезен в задачах, связанных с распознаванием образов, анализом текста и других областях, где часто встречаются повторяющиеся структуры данных. В задачах обработки естественного языка Parameter Sharing также используется для эффективного представления слов или предложений.
Например, в рекуррентных нейронных сетях один и тот же набор параметров может применяться на каждом шаге обработки последовательности данных, что позволяет эффективно работать с текстами, которые варьируются по длине, но требуют одинаковых операций на каждом этапе.
Важной характеристикой этого метода является способность к уменьшению переобучения. Когда модель содержит слишком много параметров, она может «запомнить» слишком много деталей из обучающих данных, что делает ее менее эффективной при работе с новыми данными.
Совместное использование параметров снижает риск переобучения, так как уменьшает количество свободных параметров, которые модель может подстроить под конкретные данные. Это помогает модели лучше обобщать результаты на новых, не задействованных ранее примерах.
Тем не менее, у метода есть свои ограничения. Не во всех задачах или архитектурах нейронных сетей можно эффективно применять совместное использование параметров. Например, в сложных моделях, где разные части сети должны обрабатывать различные типы данных или выполнять разные задачи, каждый параметр может иметь уникальную роль. Обобщить их не получится.
Кроме того, Parameter Sharing требует продуманной настройки и разработки архитектуры модели. Важно определить, какие параметры действительно можно использовать совместно, а какие требуют индивидуальной настройки для оптимальной работы модели. Это может потребовать дополнительных этапов экспериментов и тестирования, чтобы найти оптимальный баланс.
Заключение
Оптимизация моделей ИИ – безусловно важный процесс, который помогает уменьшить их размер и повысить эффективность без значительной потери точности. Разные методы, такие как pruning, sparse matrix representation, knowledge distillation и другие, рассмотренные выше, подходят для различных задач и условий.
Выбор правильного метода зависит от целей: где-то важна экономия памяти, а где-то скорость работы. Главное – найти баланс между производительностью и точностью, чтобы модель оставалась эффективной и при этом легко внедрялась в практические приложения.
